微服务下使用GraphQL构建BFF
微服务下使用GraphQL构建BFF
微服务架构,这个在几年前还算比较前卫的技术在如今遍地开花。得益于开源社区的支持,我们可以轻松地利用 Spring Cloud 以及 Docker 容器化快速搭建一个微服务架构的原型。不管是成熟的互联网公司、创业公司还是个人开发者,对于微服务架构的接纳程度都相当高,微服务架构的广泛应用也自然促进了技术本身更好的发展以及更多的实践。本文将结合项目实践,剖析在微服务的背景下,如何通过前后端分离的方式开发移动应用。
对于微服务本身,我们可以参考 Martin Fowler 对 Microservice 的阐述。简单说来,微服务是一种架构风格。通过对特定业务领域的分析与建模,将复杂的应用分解成小而专一、耦合度低并且高度自治的一组服务。微服务中的每个服务都是很小的应用,这些应用服务相互独立并且可部署。微服务通过对复杂应用的拆分,达到简化应用的目的,而这些耦合度较低的服务则通过 API 形式进行通信,所以服务之间对外暴露的都是 API,不管是对资源的获取还是修改。
微服务架构的这种理念,和前后端分离的理念不谋而合,前端应用控制自己所有的 UI 层面的逻辑,而数据层面则通过对微服务系统的 API 调用完成。以 JSP (Java Server Pages) 为代表的前后端交互方式也逐渐退出历史舞台。前后端分离的迅速发展也得益于前端 Web 框架 (Angular, React 等) 的不断涌现,单页面应用(Single Page Application)迅速成为了一种前端开发标准范式。加之移动互联网的发展,不管是 Mobile Native 开发方式,还是 React Native / PhoneGap 之流代表的 Hybrid 应用开发方式,前后端分离让 Web 和移动应用成为了**客户端。**客户端只需要通过 API 进行资源的查询以及修改即可。
GraphQL
一种用于 API 的查询语言
GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。 GraphQL 对你的 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
GraphQL优缺点
GraphQL 的优点
接下来会列举在应用中使用 GraphQL 的主要优点。
声明式地数据获取
如之前看到的那样,GraphQL 在使用查询语句式,使用声明式的方式获取数据。客户端在一个查询请求中,选择需要的数据和相关的字段实体。客户端根据其 UI 来决定需要的字段。你可以说这是 UI 驱动地数据获取。比方说,Airbnb 使用 GraphQL的例子,在 Airbnb 中的一个搜索界面,经常需要搜索房屋的住房体验和其他相关的一些信息,为了能在一个请求中检索所有的数据,一个 GraphQL 查询会根据 UI 选择数据中的一部分达到完美的匹配。毕竟,GraphQL 提供了极佳的关注点分离方式:客户端知道它需要什么数据,服务端知道数据的结构,以及如何从一些数据源(比如数据库、微服务、第三方 API)中拉取数据。
在 GraphQL 中没有过度获取
使用 GraphQL 不会存在过度获取的现象。使用与 Web 客户端公用的一个 RESTful API,一个移动客户端很可能会获取过多的数据,但是使用同样的 GraphQL API,移动客户端可以选择和 Web 客户端不同的数据字段。因此移动客户端能减少获取的信息,因为相对于 Web 应用的更大的屏幕,小屏幕上可能显示不了那么多信息。GraphQL 通过最开始按客户端需求选择数据,减少了传输数据的大小。
在 React、Angular、Node 和 Co 中的 GraphQL
GraphQL 并不只让 React 的开发者激动。即便 Facebook 只展示了一个使用 React 的客户端程序,但是它和任何前端或者后端的解决方案是解耦的,无关的。GraphQL 的相关实现是用 JavaScript 写的,因此 GraphQL 可以用在 Angular、Vue、Express、Hapi、Koa 以及任何其他客户端或者服务端的 JavaScript 类库上,并且这还只是在 JavaScript 的生态中。GraphQL 模仿了让 REST 这么流行的一个特点:一个两个实体(比如服务端和客户端)语言无关的接口(查询语言)。这样你可以在任意编程语言中通过使用一个 GraphQL 标准的实现使用 GraphQL 了。
单一数据源
在 GraphQL 应用中存在者单一数据源:GraphQL schema。它提供了一个所有可用数据检索的源头。鉴于 GraphQL 的 schema 通常会在服务端定义,客户端可以基于 schema 读取(query)和写入(mutation)数据。因此,服务端提供了所有可用的信息,客户端只需要执行 GraphQL 查询获取部分数据,或者通过 GraphQL 修改变更部分数据。
拼接 GraphQL Schema
拼接 Schema 使得多个 schema 可以聚合成一个。什么时候你需要考虑这个?考虑一下后端的微服务架构。每个微服务处理特定域的业务逻辑和数据。因此,每个微服务都可以定义自己的GraphQL架构。之后,使用 Schema 拼接将所有 Schema 聚合到一个可以被客户端访问的 Schema 中。最终,每个微服务都可以拥有自己的 GraphQL 端点,而一个 GraphQL API网关将所有 schema 合并到一个全局 schema 中,以便使得客户端可以使用。
GraphQL 自省
GraphQL 自省允许通过 GraphQL API 检索 GraphQL schema。因为 schema 包含了 GraphQL API 可以获得的所有数据信息,本身就是一份完美的自动生成的 API 文档。不仅仅是 API 的文档,也允许客户端通过mock GraphQL 的 schema 达到测试的目的,或者使用 schema 拼接的接口检索多个微服务的 schema。
强类型的 GraphQL
GraphQL 是一门强类型的查询语言,因为它是通过 GraphQL Schema Definition Language(SDL)书写的。因为有了强类型,它就拥有了强类型编程语言一样的好处:更不容出错、可以在编辑期验证并且支持编辑器智能补全和验证相关的集成。
GraphQL 版本化
在 GraphQL 中没有 API 版本的说法。在 REST 中,通常会提供一个 API 的多个版本(比如 api.domain.com/v1/、api.domain.com/v2/),因为随着时间过去,可能资源的结构也会发生变化。在 GraphQL 中,API 废弃可以做到字段级别,因此当一个客户端减少到一个废弃的字段,会得到一个废弃相关的警告。当没有客户端再使用这个废弃知道后,就可以从 schema 汇总移除这个字段了。这让一个 GraphQL API 不需要使用版本化的方式来演进。
成长中的 GraphQL 生态
GraphQL 的生态正在发展壮大。不仅仅是 GraphQL 天然的强类型特性适宜集成编辑器和 IDE 的演进,GraphQL 相关的应用也在演进。你可能记得在处理 REST API 的时候的 Postman,现在有 GraphiQL 或者 GraphQL Playground可以调试你的应用。你也可以找到如 Gatsby.js 这样的使用 GraphQL 的 React 静态页面生成器。比如,使用 Gatsby.js 你可以在构建时期通过一个 GraphQL 来提供你的博客内容来源。你可能还听说过内容管理系统(CMS)(比如 GraphCMS)通过 GraphQL API 来提供(博客)内容。不仅在技术领域有所演进,这还有很多 GraphQL 相关 大会、聚会和社区不断涌现,并且也可以通过一些 newsletters 和 podcast 了解到 GraphQL。
我应该全部投入到 GraphQL 么?
采用 GraphQL 并不需要将现有技术栈全部一步推翻。如果你计划从一个单体后端应用迁移到一个微服务架构上去,正是一个绝好的时机为新的微服务引入 GraphQL API。当有多个微服务时,你的团队可以通过 schema 拼接的方式引入一个 GraphQL 网关(gateway)。不过 API 网关并不是微服务中才能使用的方式,单体 REST 应用也可以。你可以通过将所有现有的 API 通过一个 API 网关不断一步一步汇集到一起,逐步完成到 GraphQL 的迁移。
GraphQL 的缺点
下面的话题展示了使用 GraphQL 的一些不足
GraphQL 查询的复杂性
人们经常错误地认为 GraphQL 就是在后端替代了数据库。并不是这样的,GraphQL 仅仅是一个查询语言。在服务端,一个查询需要解析数据,因此一个 GraphQL 相关实现常常需要执行数据库访问,但 GraphQL 其实不关心这些。还有,GraphQL 在你需要在一个查询中获取多个字段(作者、文章、评论)的时候,它对性能瓶颈没有任何帮助。无论使用 RESTful 架构还是 GraphQL,不同资源/字段仍然需要从一个数据源去获取。
因此当一个客户端需要一次查询很多嵌套字段时,前端开发通常不能很清楚他正在通过服务端访问不同的数据库获取过多的数据。这需要一种机制(比如最深查询深度、查询复杂度权重、避免递归、持久化查询)来制止来自客户端的(性能)昂贵的查询。
查询频率限制
另一个问题是频率限制,在 REST 中,可以简单的声明”一天之中,我们只允许请求这么多资源“,在一个独立的 GraphQL 操作中很难做到这一点,因为任何操作的开销都可以是廉价的或者昂贵的。这就是那些有着公共 GraphQL API 的公司提出的特定速率限制计算,通常可以归结为前面提到的最大查询深度和查询复杂度权重问题。
GraphQL 缓存
一个简单缓存,相比 REST,在 GraphQL 中实现会变得极其复杂。在 REST 中你通过 URL 访问资源,因此你可以在资源级别实现缓存,因为资源使用 URL 作为其标识符。在 GraphQL 中就复杂了,因为即便它操作的是同一个实体,每个查询都各不相同。比如,一个查询中,你可能只会请求一个作者的名字,但是在另外一次查询中你可能也想知道他的电子邮箱地址。这就需要你有一个更加健全的机制中来确保字段级别的缓存,实现起来并不简单。不过,多数基于 GraphQL 构建的类库都提供了开箱即用的缓存机制。
为什么不用 REST 呢?
GraphQL 是通常用来连接客户端和服务端的 RESTful 架构的替代方案。在前面的内容中,你已经多次听到 REST 了,那么什么是使用 GraphQL 而不是 RESTful ,显而易见的好处呢?
因为 REST 提出通过 URL 来标识资源,最终常常会出现低效的连续请求。比方说,最开始你通过 id 来定位一个作者实体,然后你通过作者的 id 获取的某个信息来请求他所有的文章。在 GraphQL 中只需要一个请求就能办到,这是更加效率的。更进一步而言,如果你想只想获取作者的所有文章数据,而不关心作者的信息,GraphQL 允许只你选择你需要的信息。在 REST 中,你需要先获取作者的所有实体信息,即使你值关心被这个作者写的文章而已。因为过度获取这个问题,只有在使用 REST 才会出现,而 GraphQL 就不会。
现在客户端应用不适合 RESTful 的服务端应用了。比方说,在 Airbnb 平台上,获取搜索结果,它为你展示了房屋、住房体验以及其他相关信息。住房和住房体验在各自的 RESTful 资源中,那么你需要支持多个网络请求。当使用 GraphQL API,你只需要在一个 GraphQL 查询中一起获取所有需要的实体(比如住房和住房体验)或者嵌套的其他相关信息(比如作者的文章信息)。
最终 GraphQL 将数据有服务端主导返回什么数据变成了客户端决定需要什么什么。这就是一开始 GraphQL 被发明的原因,因为在 Facebook 的一个移动应用和他们的 web 应用需要的数据是不一样的。
总之,仍然有些场景下使用 REST 来沟通客户端和服务端是有价值的途径,通常应用是资源驱动,也不需要像 GraphQL 这些的查询语言提供的灵活能力。然而,我还是推荐你尝试使用 GraphQL 来开发你的下一个客户/服务端架构。
BFF 概况及演进
Backend for Frontends(以下简称BFF) 顾名思义,是为前端而存在的后端(服务)中间层。即传统的前后端分离应用中,前端应用直接调用后端服务,后端服务再根据相关的业务逻辑进行数据的增删查改等。那么引用了 BFF 之后,前端应用将直接和 BFF 通信,BFF 再和后端进行 API 通信,所以本质上来说,BFF 更像是一种“中间层”服务。下图看到没有BFF以及加入BFF的前后端项目上的主要区别。
1. 没有BFF 的前后端架构
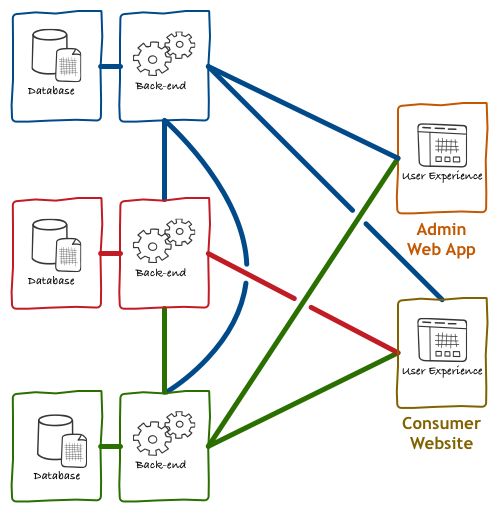
在传统的前后端设计中,通常是 App 或者 Web 端直接访问后端服务,后台微服务之间相互调用,然后返回最终的结果给前端消费。对于客户端(特别是移动端)来说,过多的 HTTP 请求是很昂贵的,所以开发过程中,为了尽量减少请求的次数,前端一般会倾向于把有关联的数据通过一个 API 获取。在微服务模式下,意味着有时为了迎合客户端的需求,服务器常会做一些与UI有关的逻辑处理。
2. 加入了BFF 的前后端架构
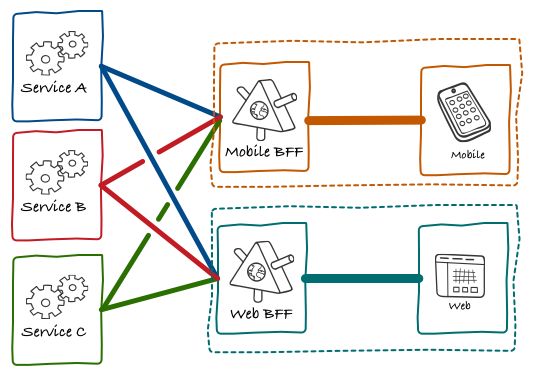
加入了BFF的前后端架构中,最大的区别就是前端(Mobile, Web) 不再直接访问后端微服务,而是通过 BFF 层进行访问。并且每种客户端都会有一个BFF服务。从微服务的角度来看,有了 BFF 之后,微服务之间的相互调用更少了。这是因为一些UI的逻辑在 BFF 层进行了处理。
BFF 和 API Gateway
从上文对 BFF 的了解来看,BFF 既然是前后端访问的中间层服务,那么 BFF 和 API Gateway 有什么区别呢?我们首先来看下 API Gateway 常见的实现方式。(API Gateway 的设计方式可能很多,这里只列举如下三种)
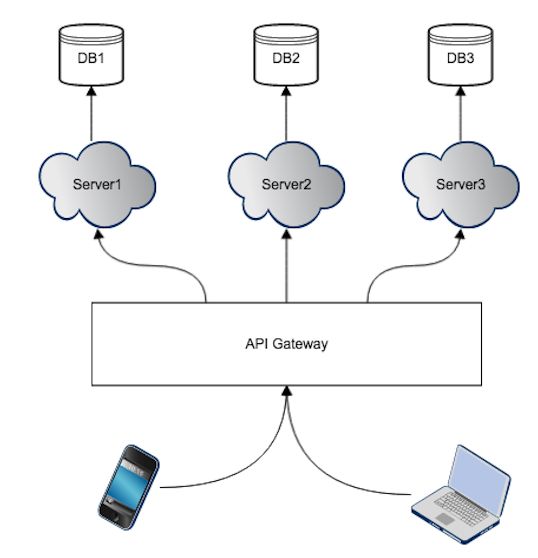
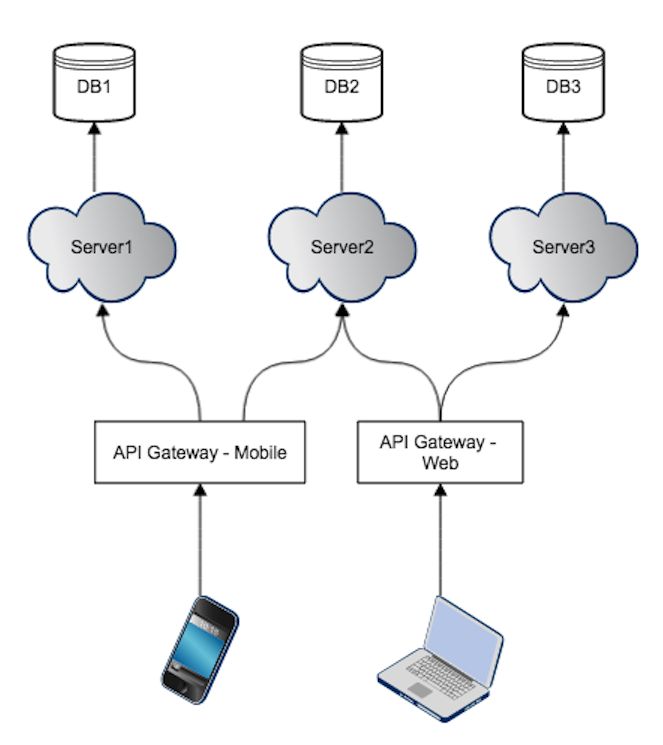
1. API Gateway 的第一种实现:一个 API Gateway 对所有客户端提供同一种 API
单个 API Gateway 实例,为多种客户端提供同一种API服务,这种情况下,API Gateway 不对客户端类型做区分。即所有 /api/users的处理都是一致的,API Gateway 不做任何的区分。如下图所示:
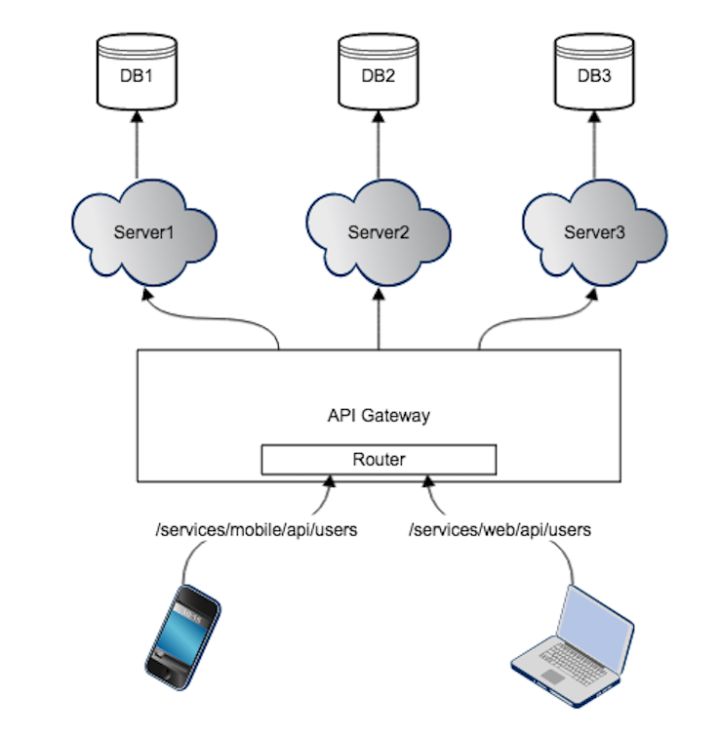
2. API Gateway 的第二种实现:一个 API Gateway 对每种客户端提供分别的 API
单个 API Gateway 实例,为多种客户端提供各自不同的API。比如对于 users 列表资源的访问,web 端和 App 端分别通过 /services/mobile/api/users, /services/web/api/users服务。API Gateway 根据不同的 API 判定来自于哪个客户端,然后分别进行处理,返回不同客户端所需的资源。
3. API Gateway 的第三种实现:多个 API Gateway 分别对每种客户端提供分别的 API
在这种实现下,针对每种类型的客户端,都会有一个单独的 API Gateway 响应其 API 请求。所以说 BFF 其实是 API Gateway 的其中一种实现模式。
GraphQL 与 REST
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
GraphQL 作为一种 API 查询语句,于2015年被 Facebook 推出,主要是为了替代传统的 REST 模式,那么对于 GraphQL 和 REST 究竟有哪些异同点呢?我们可以通过下面的例子进行理解。
按照 REST 的设计标准来看,所有的访问都是基于对资源的访问(增删查改)。如果对系统中 users 资源的访问,REST 可能通过下面的方式访问:
Request:
1 | GET http://localhost/api/users |
Response:
1 | [ |
- 对于同样的请求如果用 GraphQL 来访问,过程如下:
Request:
1 | POST http://localhost/graphql |
Body:
1 | query {users { id, name, avatar } } |
Response:
1 | { |
关于 GraphQL 更详细的用法,我们可以通过查看文档以及其他文章更加详细的去了解。相比于 REST 风格,GraphQL 具有如下特性:
1. 定义数据模型:按需获取
GraphQL 在服务器实现端,需要定义不同的数据模型。前端的所有访问,最终都是通过 GraphQL 后端定义的数据模型来进行映射和解析。并且这种基于模型的定义,能够做到按需索取。比如对上文 /users 资源的获取,如果客户端只关心 user.id, user.name 信息。那么在客户端调用的时候,query 中只需要传入 users {id \n name}即可。后台定义模型,客户端只需要获取自己关心的数据即可。
2. 数据分层
查询一组users数据,可能需要获取 user.friends, user.friends.addr 等信息,所以针对 users 的本次查询,实际上分别涉及到对 user, frind, addr三类数据。GraphQL 对分层数据的查询,大大减少了客户端请求次数。因为在 REST 模式下,可能意味着每次获取 user 数据之后,需要再次发送 API 去请求 friends 接口。而 GraphQL 通过数据分层,能够让客户端通过一个 API获取所有需要的数据。这也就是 GraphQL(图查询语句 Graph Query Language)名称的由来。
1 | { |
3. 强类型
1 | const Meeting = new GraphQLObjectType({ |
GraphQL 的类型系统定义了包括 Int, Float, String, Boolean, ID, Object, List, Non-Null 等数据类型。所以在开发过程中,利用强大的强类型检查,能够大大节省开发的时间,同时也很方便前后端进行调试。
4. 协议而非存储
GraphQL 本身并不直接提供后端存储的能力,它不绑定任何的数据库或者存储引擎。它利用已有的代码和技术进行数据源的管理。比如作为在 BFF 层使用 GraphQL, 这一层的 BFF 并不需要任何的数据库或者存储媒介。GraphQL 只是解析客户端请求,知道客户端的“意图”之后,再通过对微服务API的访问获取到数据,对数据进行一系列的组装或者过滤。
5. 无须版本化
1 | const PhotoType = new GraphQLObjectType({ |
GraphQL 服务端能够通过添加 deprecationReason,自动将某个字段标注为弃用状态。并且基于 GraphQL 高度的可扩展性,如果不需要某个数据,那么只需要使用新的字段或者结构即可,老的弃用字段给老的客户端提供服务,所有新的客户端使用新的字段获取相关信息。并且考虑到所有的 graphql 请求,都是按照 POST /graphql 发送请求,所以在 GraphQL 中是无须进行版本化的。
GraphQL 和 REST
对于 GraphQL 和 REST 之间的对比,主要有如下不同:
**1. 数据获取:**REST 缺乏可扩展性, GraphQL 能够按需获取。GraphQL API 调用时,payload 是可以扩展的;
**2. API 调用:**REST 针对每种资源的操作都是一个 endpoint, GraphQL 只需要一个 endpoint( /graphql), 只是 post body 不一样;
**3. 复杂数据请求:**REST 对于嵌套的复杂数据需要多次调用,GraphQL 一次调用, 减少网络开销;
**4. 错误码处理:**REST 能够精确返回HTTP错误码,GraphQL 统一返回200,对错误信息进行包装;
**5. 版本号:**REST通过 v1/v2 实现,GraphQL 通过 Schema 扩展实现;
微服务 + GraphQL + BFF 实践
在微服务下基于 GraphQL 构建 BFF,我们在项目中已经开始了相关的实践。在我们项目对应的业务场景下,微服务后台有近 10 个微服务,客户端包括针对不同角色的4个 App 以及一个 Web 端。对于每种类型的 App,都有一个 BFF 与之对应。每种 BFF 只服务于这个 App。BFF 解析到客户端请求之后,会通过 BFF 端的服务发现,去对应的微服务后台通过 CQRS 的方式进行数据查询或修改。
1. BFF 端技术栈

我们使用 GraphQL-express 框架构建项目的 BFF 端,然后通过 Docker 进行部署。BFF 和微服务后台之间,还是通过 registrator 和 Consul 进行服务注册和发现。
1 | addRoutes () { |
在 BFF 的路由设置中,对于客户端的处理,主要有 /graphql 和 /api/${serviceName}两部分。/graphql 处理的是所有 GraphQL 查询请求,同时我们在 BFF 端增加了 /api/${serviceName} 进行 API 透传,对于一些没有必要进行 GraphQL 封装的请求,可以直接通过透传访问到相关的微服务中。
2. 整体技术架构
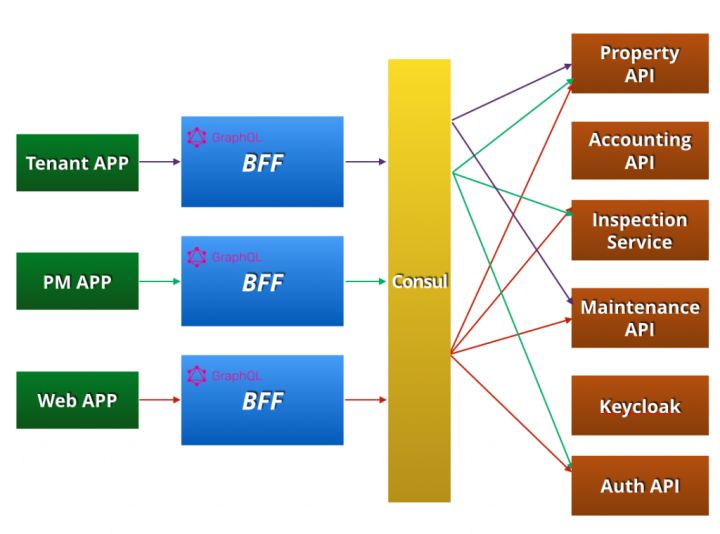
整体来看,我们的前后端架构图如下,三个 App 客户端分别使用 GraphQL 的形式请求对应的 BFF。BFF 层再通过 Consul 服务发现和后端通信。
关于系统中的鉴权问题
用户登录后,App 直接访问 KeyCloak 服务获取到 id_token,然后通过 id_token 透传访问 auth-api 服务获取到 access_token, access_token 以 JWT (Json Web Token) 的形式放置到后续 http 请求的头信息中。
在我们这个系统中 BFF 层并不做鉴权服务,所有的鉴权过程全部由各自的微服务模块负责。BFF 只提供中转的功能。BFF 是否需要集成鉴权认证,主要看各系统自己的设计,并不是一个标准的实践。
3. GraphQL + BFF 实践
通过如下几个方面,可以思考基于 GraphQL 的 BFF 的一些更好的特质:
GraphQL 和 BFF 对业务点的关注
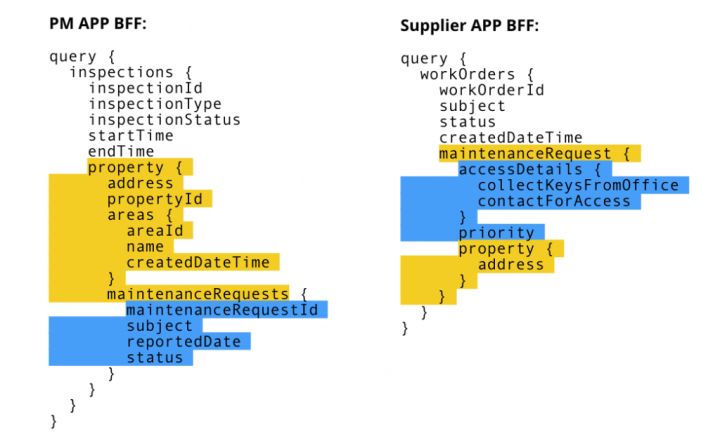
从业务上来看,PM App(使用者:物业经理)关注的是property,物业经理管理着一批房屋,所以需要知道所有房屋概况,对于每个房屋需要知道有没有对应的维修申请。所以 PM App BFF 在定义数据结构是,maintemamceRequests 是 property 的子属性。
同样类似的数据,Supplier App(使用者:房屋维修供应商)关注的是 maintenanceRequest(维修工单),所以在 Supplier App 获取的数据里,我们的主体是maintenanceRequest。维修供应商关注的是 workOrder.maintenanceRequest。
所以不同的客户端,因为存在着不同的使用场景,所以对于同样的数据却有着不同的关注点。BFF is pary of Application。从这个角度来看,BFF 中定义的数据结构,就是客户端所真正关心的。BFF 就是为客户端而生,是客户端的一部分。需要说明的是,对于“业务的关注”并不是说,BFF会处理所有的业务逻辑,业务逻辑还是应该由微服务关心,BFF 关注的是客户端需要什么。
GraphQL 对版本化的支持
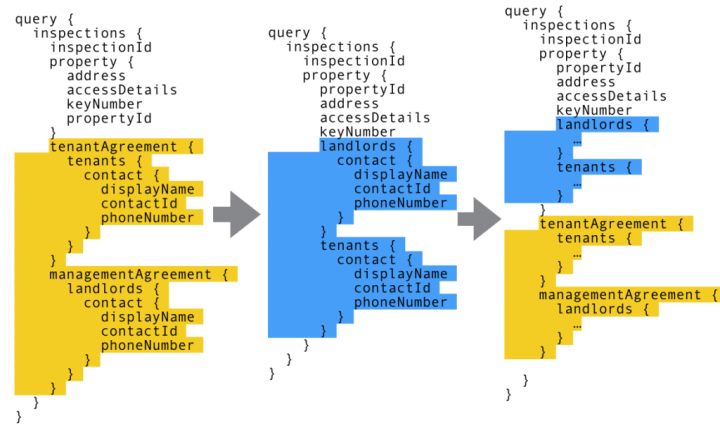
假设 BFF 端已经发布到生产环境,提供了 inspection 相关的 tenants 和 landlords 的查询。现在需要将图一的结构变更为图二的结构,但是为了不影响老用户的 API 访问,这时候我们的 BFF API 必须进行兼容。如果在 REST 中,可能会增加 api/v2/inspections进行 API 升级。但是在 BFF 中,为了向前兼容,我们可以使用图三的结构。这时候老的 APP 使用黄色区域的数据结构,而新的 APP 则使用蓝色区域定义的结构。
GraphQL Mutation 与 CQRS
1 | mutation { |
如果你详细阅读了 GraphQL 的文档,可以发现 GraphQL 对 query 和 mutation 进行了分离。所有的查询应该使用 query { ...},相应的 mutaition 需要使用 mutation { ... }。虽然看起来像是一个convention,但是 GraphQL 的这种设计和后端 API 的 读写职责分离(Command Query Responsibility Segregation)不谋而合。而实际上我们使用的时候也遵从这个规范。所以的 mutation 都会调用后台的 API,而后端的 API 对于资源的修改也是通过 SpringBoot EventListener 实现的 CQRS 模式。
如何做好测试
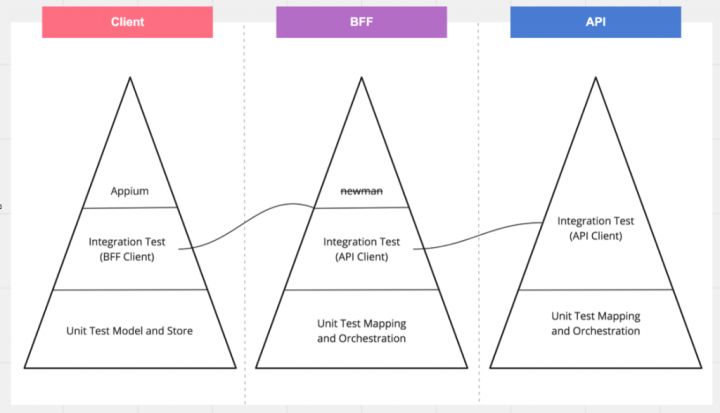
在引入了 BFF 的项目,我们的测试仍然使用金字塔原理,只是在客户端和后台之间,需要添加对 BFF 的测试。
- Client 的 integration-test 关心的是 App 访问 BFF 的连通性,App 中所有访问 BFF 的请求都需要进行测试;
- BFF 的 integration-test 测试的是 BFF 到微服务 API 的连通性,BFF 中依赖的所有 API 都应该有集成测试的保障;
- API 的 integration-test 关注的是这个服务对外暴露的所有 API,通常测试所有的 Controller 中的 API;
结语
微服务下基于 GraphQL 构建 BFF 并不是银弹,也并不一定适合所有的项目,比如当你使用 GraphQL 之后,你可能得面临多次查询性能问题等,但这不妨碍它成为一个不错的尝试。你也的确看到 Facebook 早已经使用 GraphQL,而且 Github 也开放了 GraphQL 的API。而 BFF, 其实很多团队也都已经在实践了,在微服务下等特殊场景下,GraphQL + BFF 也许可以给你的项目带来惊喜。
参考资料
【注】部分图片来自网络
- https://martinfowler.com/articles/microservices.html
- https://www.thoughtworks.com/insights/blog/bff-soundcloud
- http://philcalcado.com/2015/09/18/thebackendforfrontendpattern_bff.html
- http://samnewman.io/patterns/architectural/bff
- https://medium.com/netflix-techblog/embracing-the-differences-inside-the-netflix-api-redesign-15fd8b3dc49d
参考项目
https://github.com/wangyangyangisme/wolf-bff
https://github.com/wangyangyangisme/front-bff-msa
https://github.com/wangyangyangisme/backend-bff
https://github.com/wangyangyangisme/try-bff
https://github.com/wangyangyangisme/gospiga redisrearch全文收索
鉴权
在官方的描述中,GraphQL和RESTful API一样,建议开发者将授权逻辑委托给业务逻辑层:
n+1
dataloader
https://github.com/vektah/dataloaden
https://github.com/graph-gophers/dataloader
相关文章
https://www.jianshu.com/p/43dae0b83755 REST服务与RestfulAPI风格
https://blog.csdn.net/z69183787/article/details/79992285 微服务下使用GraphQL构建BFF
https://www.jianshu.com/p/798b610dca32 使用 GraphQL 构建 BFF Demo
https://cloud.tencent.com/developer/article/1477870 GraphQL-BFF:微服务背景下的前后端数据交互方案
https://www.sohu.com/a/235978606_205771 干货分享 | GraphQL 数据聚合层
https://www.jianshu.com/p/b420a33eeeab GraphQL服务开发指南
https://cloud.tencent.com/developer/article/1336237 一位前端专家构建GraphQL工程的心路历程
https://zhuanlan.zhihu.com/p/44140864 精读《REST, GraphQL, gRPC 如何选型》
https://github.com/maticzav/graphql-shield
https://zhuanlan.zhihu.com/p/141629697 代码之上:我们落地 GraphQL 背后的故事
https://zhuanlan.zhihu.com/p/45944392 从头用go写一个GraphQL服务(3)OpenTracing追踪
https://haofly.net/graphql-tutorial-6/ n+1问题 https://github.com/vektah/dataloaden https://github.com/graph-gophers/dataloader


