GraphQL文档
GraphQL文档
GraphQL 入门
在接下来的一系列文章中,我们会了解 GraphQL 是什么,它是如何运作以及如何使用它。在找如何搭建 GraphQL 服务的文档?这有一些类库可以帮你用多种不同语言实现 GraphQL。通过实用教程深入学习体验,请访问 How to GraphQL 全栈教程网站。我们还与 edX 合作创建了免费的在线课程,探索 GraphQL:一种用于 API 的查询语言。
GraphQL 是一个用于 API 的查询语言,是一个使用基于类型系统来执行查询的服务端运行时(类型系统由你的数据定义)。GraphQL 并没有和任何特定数据库或者存储引擎绑定,而是依靠你现有的代码和数据支撑。
一个 GraphQL 服务是通过定义类型和类型上的字段来创建的,然后给每个类型上的每个字段提供解析函数。例如,一个 GraphQL 服务告诉我们当前登录用户是 me,这个用户的名称可能像这样:
1 | type Query { |
一并的还有每个类型上字段的解析函数:
1 | function Query_me(request) { |
一旦一个 GraphQL 服务运行起来(通常在 web 服务的一个 URL 上),它就能接收 GraphQL 查询,并验证和执行。接收到的查询首先会被检查确保它只引用了已定义的类型和字段,然后运行指定的解析函数来生成结果。
例如这个查询:
1 | { |
会产生这样的JSON结果:
1 | { |
在这系列文章中,我们会学习更多关于 GraphQL 的知识,包括查询语言、类型系统、GraphQL 服务的工作原理以及使用 GraphQL 解决常见问题的最佳实践。
查询和变更
你可以在本页学到有关如何查询 GraphQL 服务器的详细信息。
字段(Fields)
简单而言,GraphQL 是关于请求对象上的特定字段。我们以一个非常简单的查询以及其结果为例:
1 | { |
1 | { |
你立即就能发现,查询和其结果拥有几乎一样的结构。这是 GraphQL 最重要的特性,因为这样一来,你就总是能得到你想要的数据,而服务器也准确地知道客户端请求的字段。
name 字段返回 String 类型,在这个示例中是《星球大战》主角的名字是:"R2-D2"。
对了,还有一点 —— 上述查询是可交互的。也就是你可以按你喜欢来改变查询,然后看看新的结果。尝试给查询中的
hero对象添加一个appearsIn字段,看看新的结果吧。
在前一例子中,我们请求了我们主角的名字,返回了一个字符串类型(String),但是字段也能指代对象类型(Object)。这个时候,你可以对这个对象的字段进行次级选择(sub-selection)。GraphQL 查询能够遍历相关对象及其字段,使得客户端可以一次请求查询大量相关数据,而不像传统 REST 架构中那样需要多次往返查询。
1 | { |
1 | { |
注意这个例子中,friends 返回了一个数组的项目,GraphQL 查询会同等看待单个项目或者一个列表的项目,然而我们可以通过 schema 所指示的内容来预测将会得到哪一种。
参数(Arguments)
即使我们能做的仅仅是遍历对象及其字段,GraphQL 就已经是一个非常有用的数据查询语言了。但是当你加入给字段传递参数的能力时,事情会变得更加有趣。
1 | { |
1 | { |
在类似 REST 的系统中,你只能传递一组简单参数 —— 请求中的 query 参数和 URL 段。但是在 GraphQL 中,每一个字段和嵌套对象都能有自己的一组参数,从而使得 GraphQL 可以完美替代多次 API 获取请求。甚至你也可以给 标量(scalar)字段传递参数,用于实现服务端的一次转换,而不用每个客户端分别转换。
1 | { |
1 | { |
参数可以是多种不同的类型。上面例子中,我们使用了一个枚举类型,其代表了一个有限选项集合(本例中为长度单位,即是 METER 或者 FOOT)。GraphQL 自带一套默认类型,但是 GraphQL 服务器可以声明一套自己的定制类型,只要能序列化成你的传输格式即可。
别名(Aliases)
如果你眼睛够锐利,你可能已经发现,即便结果中的字段与查询中的字段能够匹配,但是因为他们并不包含参数,你就没法通过不同参数来查询相同字段。这便是为何你需要别名 —— 这可以让你重命名结果中的字段为任意你想到的名字。
1 | { |
1 | { |
上例中,两个 hero 字段将会存在冲突,但是因为我们可以将其另取一个别名,我们也就可以在一次请求中得到两个结果。
片段(Fragments)
假设我们的 app 有比较复杂的页面,将正反派主角及其友军分为两拨。你立马就能想到对应的查询会变得复杂,因为我们需要将一些字段重复至少一次 —— 两方各一次以作比较。
这就是为何 GraphQL 包含了称作片段的可复用单元。片段使你能够组织一组字段,然后在需要它们的的地方引入。下面例子展示了如何使用片段解决上述场景:
1 | { |
1 | { |
你可以看到上面的查询如何漂亮地重复了字段。片段的概念经常用于将复杂的应用数据需求分割成小块,特别是你要将大量不同片段的 UI 组件组合成一个初始数据获取的时候。
在片段内使用变量
片段可以访问查询或变更中声明的变量。详见 变量。
1 | query HeroComparison($first: Int = 3) { |
1 | { |
操作名称(Operation name)
这之前,我们都使用了简写句法,省略了 query 关键字和查询名称,但是生产中使用这些可以使我们代码减少歧义。
下面的示例包含了作为操作类型的关键字 query 以及操作名称 HeroNameAndFriends:
1 | query HeroNameAndFriends { |
1 | { |
操作类型可以是 query、mutation 或 subscription,描述你打算做什么类型的操作。操作类型是必需的,除非你使用查询简写语法,在这种情况下,你无法为操作提供名称或变量定义。
操作名称是你的操作的有意义和明确的名称。它仅在有多个操作的文档中是必需的,但我们鼓励使用它,因为它对于调试和服务器端日志记录非常有用。 当在你的网络或是 GraphQL 服务器的日志中出现问题时,通过名称来从你的代码库中找到一个查询比尝试去破译内容更加容易。 就把它想成你喜欢的程序语言中的函数名。例如,在 JavaScript 中,我们只用匿名函数就可以工作,但是当我们给了函数名之后,就更加容易追踪、调试我们的代码,并在其被调用的时候做日志。同理,GraphQL 的查询和变更名称,以及片段名称,都可以成为服务端侧用来识别不同 GraphQL 请求的有效调试工具。
变量(Variables)
目前为止,我们将参数写在了查询字符串内。但是在很多应用中,字段的参数可能是动态的:例如,可能是一个"下拉菜单"让你选择感兴趣的《星球大战》续集,或者是一个搜索区,或者是一组过滤器。
将这些动态参数直接传进查询字符串并不是好主意,因为这样我们的客户端就得动态地在运行时操作这些查询字符串了,再把它序列化成 GraphQL 专用的格式。其实,GraphQL 拥有一级方法将动态值提取到查询之外,然后作为分离的字典传进去。这些动态值即称为变量。
使用变量之前,我们得做三件事:
- 使用
$variableName替代查询中的静态值。 - 声明
$variableName为查询接受的变量之一。 - 将
variableName: value通过传输专用(通常是 JSON)的分离的变量字典中。
全部做完之后就像这个样子:
1 | # { "graphiql": true, "variables": { "episode": JEDI } } |
这样一来,我们的客户端代码就只需要传入不同的变量,而不用构建一个全新的查询了。这事实上也是一个良好实践,意味着查询的参数将是动态的 —— 我们决不能使用用户提供的值来字符串插值以构建查询。
变量定义(Variable definitions)
变量定义看上去像是上述查询中的 ($episode: Episode)。其工作方式跟类型语言中函数的参数定义一样。它以列出所有变量,变量前缀必须为 $,后跟其类型,本例中为 Episode。
所有声明的变量都必须是标量、枚举型或者输入对象类型。所以如果想要传递一个复杂对象到一个字段上,你必须知道服务器上其匹配的类型。可以从Schema页面了解更多关于输入对象类型的信息。
变量定义可以是可选的或者必要的。上例中,Episode 后并没有 !,因此其是可选的。但是如果你传递变量的字段要求非空参数,那变量一定是必要的。
如果想要进一步了解变量定义的句法,可以学习 GraphQL 的 schema 语言。schema 语言在 Schema 中有细述。
默认变量(Default variables)
可以通过在查询中的类型定义后面附带默认值的方式,将默认值赋给变量。
1 | query HeroNameAndFriends($episode: Episode = "JEDI") { |
当所有变量都有默认值的时候,你可以不传变量直接调用查询。如果任何变量作为变量字典的部分传递了,它将覆盖其默认值。
指令(Directives)
我们上面讨论的变量使得我们可以避免手动字符串插值构建动态查询。传递变量给参数解决了一大堆这样的问题,但是我们可能也需要一个方式使用变量动态地改变我们查询的结构。譬如我们假设有个 UI 组件,其有概括视图和详情视图,后者比前者拥有更多的字段。
我们来构建一个这种组件的查询:
1 | query Hero($episode: Episode, $withFriends: Boolean!) { |
1 | { |
1 | { |
尝试修改上面的变量,传递 true 给 withFriends,看看结果的变化。
我们用了 GraphQL 中一种称作指令的新特性。一个指令可以附着在字段或者片段包含的字段上,然后以任何服务端期待的方式来改变查询的执行。GraphQL 的核心规范包含两个指令,其必须被任何规范兼容的 GraphQL 服务器实现所支持:
@include(if: Boolean)仅在参数为true时,包含此字段。@skip(if: Boolean)如果参数为true,跳过此字段。
指令在你不得不通过字符串操作来增减查询的字段时解救你。服务端实现也可以定义新的指令来添加新的特性。
变更(Mutations)
GraphQL 的大部分讨论集中在数据获取,但是任何完整的数据平台也都需要一个改变服务端数据的方法。
REST 中,任何请求都可能最后导致一些服务端副作用,但是约定上建议不要使用 GET 请求来修改数据。GraphQL 也是类似 —— 技术上而言,任何查询都可以被实现为导致数据写入。然而,建一个约定来规范任何导致写入的操作都应该显式通过变更(mutation)来发送。
就如同查询一样,如果任何变更字段返回一个对象类型,你也能请求其嵌套字段。获取一个对象变更后的新状态也是十分有用的。我们来看看一个变更例子:
1 | mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) { |
1 | { |
1 | { |
注意 createReview 字段如何返回了新建的 review 的 stars 和 commentary 字段。这在变更已有数据时特别有用,例如,当一个字段自增的时候,我们可以在一个请求中变更并查询这个字段的新值。
你也可能注意到,这个例子中,我们传递的 review 变量并非标量。它是一个输入对象类型,一种特殊的对象类型,可以作为参数传递。你可以在 Schema 页面上了解到更多关于输入类型的信息。
变更中的多个字段(Multiple fields in mutations)
一个变更也能包含多个字段,一如查询。查询和变更之间名称之外的一个重要区别是:
查询字段时,是并行执行,而变更字段时,是线性执行,一个接着一个。
这意味着如果我们一个请求中发送了两个 incrementCredits 变更,第一个保证在第二个之前执行,以确保我们不会出现竞态。
内联片段(Inline Fragments)
跟许多类型系统一样,GraphQL schema 也具备定义接口和联合类型的能力。在 schema 指南中可了解更多。
如果你查询的字段返回的是接口或者联合类型,那么你可能需要使用内联片段来取出下层具体类型的数据:
1 | query HeroForEpisode($ep: Episode!) { |
1 | { |
1 | { |
这个查询中,hero 字段返回 Character 类型,取决于 episode 参数,其可能是 Human 或者 Droid 类型。在直接选择的情况下,你只能请求 Character 上存在的字段,譬如 name。
如果要请求具体类型上的字段,你需要使用一个类型条件内联片段。因为第一个片段标注为 ... on Droid,primaryFunction 仅在 hero 返回的 Character 为 Droid 类型时才会执行。同理适用于 Human 类型的 height 字段。
具名片段也可以用于同样的情况,因为具名片段总是附带了一个类型。
元字段(Meta fields)
某些情况下,你并不知道你将从 GraphQL 服务获得什么类型,这时候你就需要一些方法在客户端来决定如何处理这些数据。GraphQL 允许你在查询的任何位置请求 __typename,一个元字段,以获得那个位置的对象类型名称。
1 | { |
1 | { |
上面的查询中,search 返回了一个联合类型,其可能是三种选项之一。没有 __typename 字段的情况下,几乎不可能在客户端分辨开这三个不同的类型。
GraphQL 服务提供了不少元字段,剩下的部分用于描述 内省 系统。
Schema 和类型
在本页,你将学到关于 GraphQL 类型系统中所有你需要了解的知识,以及类型系统如何描述可以查询的数据。因为 GraphQL 可以运行在任何后端框架或者编程语言之上,我们将摒除实现上的细节而仅仅专注于其概念。
GraphQL 服务端的应用代码的基本实现流程
- 定义用户自定义类型。类型的每个字段都必须是已定义的,且最终都是 GraphQL 中定义的类型。
- 定义根类型。每种根类型中包含了准备暴露给服务调用方的用户自定义类型。
- 定义 Schema。每一个 Schema 中允许出现三种根类型:query,mutation,subscription,其中至少要有 query。
每次调用 GraphQL 服务,需要明确指定调用 Schema 中的哪个根类型(默认是 query),然后指定这个根类型下的哪几个字段(每个字段对应一个用户自定义类型),然后指定这些字段中的那些子字段的哪几个。一直到所有的字段都没有子字段为止。
Schema 明确了服务端有哪些字段(用户自定义类型)可以用,每个字段的类型和子字段。每次查询时,服务器就会根据 Schema 验证并执行查询。
定义 Schema(模型),Schema 文件里有4个关键字:
- schema–表示这是一个GraphQL schema定义;
- query–定义查询操作,必须有。
- mutation–定义变更操作,可以省略。
- subscription–定义订阅操作,可以省略。
1 | schema { |
类型系统(Type System)
如果你之前见到过 GraphQL 查询,你就知道 GraphQL 查询语言基本上就是关于选择对象上的字段。因此,例如在下列查询中:
1 | { |
1 | { |
- 我们以一个特殊的对象 "root" 开始
- 选择其上的
hero字段 - 对于
hero返回的对象,我们选择name和appearsIn字段
因为一个 GraphQL 查询的结构和结果非常相似,因此即便不知道服务器的情况,你也能预测查询会返回什么结果。但是一个关于我们所需要的数据的确切描述依然很有意义,我们能选择什么字段?服务器会返回哪种对象?这些对象下有哪些字段可用?这便是引入 schema 的原因。
每一个 GraphQL 服务都会定义一套类型,用以描述你可能从那个服务查询到的数据。每当查询到来,服务器就会根据 schema 验证并执行查询。
类型语言(Type Language)
GraphQL 服务可以用任何语言编写,因为我们并不依赖于任何特定语言的句法句式(譬如 JavaScript)来与 GraphQL schema 沟通,我们定义了自己的简单语言,称之为 “GraphQL schema language” —— 它和 GraphQL 的查询语言很相似,让我们能够和 GraphQL schema 之间可以无语言差异地沟通。
对象类型和字段(Object Types and Fields)
一个 GraphQL schema 中的最基本的组件是对象类型,它就表示你可以从服务上获取到什么类型的对象,以及这个对象有什么字段。使用 GraphQL schema language,我们可以这样表示它:
1 | type Character { |
虽然这语言可读性相当好,但我们还是一起看看其用语,以便我们可以有些共通的词汇:
Character是一个 GraphQL 对象类型,表示其是一个拥有一些字段的类型。你的 schema 中的大多数类型都会是对象类型。name和appearsIn是Character类型上的字段。这意味着在一个操作Character类型的 GraphQL 查询中的任何部分,都只能出现name和appearsIn字段。String是内置的标量类型之一 —— 标量类型是解析到单个标量对象的类型,无法在查询中对它进行次级选择。后面我们将细述标量类型。String!表示这个字段是非空的,GraphQL 服务保证当你查询这个字段后总会给你返回一个值。在类型语言里面,我们用一个感叹号来表示这个特性。[Episode!]!表示一个Episode数组。因为它也是非空的,所以当你查询appearsIn字段的时候,你也总能得到一个数组(零个或者多个元素)。且由于Episode!也是非空的,你总是可以预期到数组中的每个项目都是一个Episode对象。
现在你知道一个 GraphQL 对象类型看上去是怎样,也知道如何阅读基础的 GraphQL 类型语言了。
参数(Arguments)
GraphQL 对象类型上的每一个字段都可能有零个或者多个参数,例如下面的 length 字段:
1 | type Starship { |
所有参数都是具名的,不像 JavaScript 或者 Python 之类的语言,函数接受一个有序参数列表,而在 GraphQL 中,所有参数必须具名传递。本例中,length 字段定义了一个参数,unit。
参数可能是必选或者可选的,当一个参数是可选的,我们可以定义一个默认值 —— 如果 unit 参数没有传递,那么它将会被默认设置为 METER。
查询和变更类型(The Query and Mutation Types)
你的 schema 中大部分的类型都是普通对象类型,但是一个 schema 内有两个特殊类型:
1 | schema { |
每一个 GraphQL 服务都有一个 query 类型,可能有一个 mutation 类型。这两个类型和常规对象类型无差,但是它们之所以特殊,是因为它们定义了每一个 GraphQL 查询的入口。因此如果你看到一个像这样的查询:
1 | query { |
1 | { |
那表示这个 GraphQL 服务需要一个 Query 类型,且其上有 hero 和 droid 字段:
1 | type Query { |
变更也是类似的工作方式 —— 你在 Mutation 类型上定义一些字段,然后这些字段将作为 mutation 根字段使用,接着你就能在你的查询中调用。
有必要记住的是,除了作为 schema 的入口,Query 和 Mutation 类型与其它 GraphQL 对象类型别无二致,它们的字段也是一样的工作方式。
标量类型(Scalar Types)
一个对象类型有自己的名字和字段,而某些时候,这些字段必然会解析到具体数据。这就是标量类型的来源:它们表示对应 GraphQL 查询的叶子节点。
下列查询中,name 和 appearsIn 字段将解析到标量类型:
1 | { |
1 | { |
我们知道这些字段没有任何次级字段 —— 因为让它们是查询的叶子节点。
GraphQL 自带一组默认标量类型:
Int:有符号 32 位整数。Float:有符号双精度浮点值。String:UTF‐8 字符序列。Boolean:true或者false。ID:ID 标量类型表示一个唯一标识符,通常用以重新获取对象或者作为缓存中的键。ID 类型使用和 String 一样的方式序列化;然而将其定义为 ID 意味着并不需要人类可读型。
大部分的 GraphQL 服务实现中,都有自定义标量类型的方式。例如,我们可以定义一个 Date 类型:
1 | scalar Date |
然后就取决于我们的实现中如何定义将其序列化、反序列化和验证。例如,你可以指定 Date 类型应该总是被序列化成整型时间戳,而客户端应该知道去要求任何 date 字段都是这个格式。
枚举类型(Enumeration Types)
也称作枚举(enum),枚举类型是一种特殊的标量,它限制在一个特殊的可选值集合内。这让你能够:
- 验证这个类型的任何参数是可选值的的某一个
- 与类型系统沟通,一个字段总是一个有限值集合的其中一个值。
下面是一个用 GraphQL schema 语言表示的 enum 定义:
1 | enum Episode { |
这表示无论我们在 schema 的哪处使用了 Episode,都可以肯定它返回的是 NEWHOPE、EMPIRE 和 JEDI 之一。
注意,各种语言实现的 GraphQL 服务会有其独特的枚举处理方式。对于将枚举作为一等公民的语言,它的实现就可以利用这个特性;而对于像 JavaScript 这样没有枚举支持的语言,这些枚举值可能就被内部映射成整数值。当然,这些细节都不会泄漏到客户端,客户端会根据字符串名称来操作枚举值。
列表和非空(Lists and Non-Null)
对象类型、标量以及枚举是 GraphQL 中你唯一可以定义的类型种类。但是当你在 schema 的其他部分使用这些类型时,或者在你的查询变量声明处使用时,你可以给它们应用额外的类型修饰符来影响这些值的验证。我们先来看一个例子:
1 | type Character { |
此处我们使用了一个 String 类型,并通过在类型名后面添加一个感叹号!将其标注为非空。这表示我们的服务器对于这个字段,总是会返回一个非空值,如果它结果得到了一个空值,那么事实上将会触发一个 GraphQL 执行错误,以让客户端知道发生了错误。
非空类型修饰符也可以用于定义字段上的参数,如果这个参数上传递了一个空值(不管通过 GraphQL 字符串还是变量),那么会导致服务器返回一个验证错误。
1 | query DroidById($id: ID!) { |
1 | { |
1 | { |
列表的运作方式也类似:我们也可以使用一个类型修饰符来标记一个类型为 List,表示这个字段会返回这个类型的数组。在 GraphQL schema 语言中,我们通过将类型包在方括号([ 和 ])中的方式来标记列表。列表对于参数也是一样的运作方式,验证的步骤会要求对应值为数组。
非空和列表修饰符可以组合使用。例如你可以要求一个非空字符串的数组:
1 | myField: [String!] |
这表示数组本身可以为空,但是其不能有任何空值成员。用 JSON 举例如下:
1 | myField: null // 有效 |
然后,我们来定义一个不可为空的字符串数组:
1 | myField: [String]! |
这表示数组本身不能为空,但是其可以包含空值成员:
1 | myField: null // 错误 |
你可以根据需求嵌套任意层非空和列表修饰符。
接口(Interfaces)
跟许多类型系统一样,GraphQL 支持接口。一个接口是一个抽象类型,它包含某些字段,而对象类型必须包含这些字段,才能算实现了这个接口。
例如,你可以用一个 Character 接口用以表示《星球大战》三部曲中的任何角色:
1 | interface Character { |
这意味着任何实现 Character 的类型都要具有这些字段,并有对应参数和返回类型。
例如,这里有一些可能实现了 Character 的类型:
1 | type Human implements Character { |
可见这两个类型都具备 Character 接口的所有字段,但也引入了其他的字段 totalCredits、starships 和 primaryFunction,这都属于特定的类型的角色。
当你要返回一个对象或者一组对象,特别是一组不同的类型时,接口就显得特别有用。
注意下面例子的查询会产生错误:
1 | query HeroForEpisode($ep: Episode!) { |
1 | { |
1 | { |
hero 字段返回 Character 类型,取决于 episode 参数,它可能是 Human 或者 Droid 类型。上面的查询中,你只能查询 Character 接口中存在的字段,而其中并不包含 primaryFunction。
如果要查询一个只存在于特定对象类型上的字段,你需要使用内联片段:
1 | query HeroForEpisode($ep: Episode!) { |
1 | { |
1 | { |
你可以在查询指南的 内联片段 章节了解更多相关信息。
联合类型(Union Types)
联合类型和接口十分相似,但是它并不指定类型之间的任何共同字段。
1 | union SearchResult = Human | Droid | Starship |
在我们的schema中,任何返回一个 SearchResult 类型的地方,都可能得到一个 Human、Droid 或者 Starship。注意,联合类型的成员需要是具体对象类型;你不能使用接口或者其他联合类型来创造一个联合类型。
这时候,如果你需要查询一个返回 SearchResult 联合类型的字段,那么你得使用条件片段才能查询任意字段。
1 | { |
1 | { |
_typename 字段解析为 String,它允许你在客户端区分不同的数据类型。
此外,在这种情况下,由于 Human 和 Droid 共享一个公共接口(Character),你可以在一个地方查询它们的公共字段,而不必在多个类型中重复相同的字段:
1 | { |
注意 name 仍然需要指定在 Starship 上,否则它不会出现在结果中,因为 Starship 并不是一个 Character!
输入类型(Input Types)
目前为止,我们只讨论过将例如枚举和字符串等标量值作为参数传递给字段,但是你也能很容易地传递复杂对象。这在变更(mutation)中特别有用,因为有时候你需要传递一整个对象作为新建对象。在 GraphQL schema language 中,输入对象看上去和常规对象一模一样,除了关键字是 input 而不是 type:
1 | input ReviewInput { |
你可以像这样在变更(mutation)中使用输入对象类型:
1 | mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) { |
1 | { |
1 | { |
输入对象类型上的字段本身也可以指代输入对象类型,但是你不能在你的 schema 混淆输入和输出类型。输入对象类型的字段当然也不能拥有参数。
验证
通过使用类型系统,你可以预判一个查询是否有效。这让服务器和客户端可以在无效查询创建时就有效地通知开发者,而不用依赖运行时检查。
对于我们的《星球大战》的案例,starWarsValidation-test.js 这个文件包含了若干对于各种无效查询的演示,它也是一个测试文件,用于检测参考实现的验证器。
1 | { |
1 | { |
上面这个查询是有效的。我们来看看一些无效查询……
片段不能引用其自身或者创造回环,因为这会导致结果无边界。下面是一个相同的查询,但是没有显式的三层嵌套:
1 | { |
1 | { |
查询字段的时候,我们只能查询给定类型上的字段。因此由于 hero 返回 Character 类型,我们只能查询 Character 上的字段。因为这个类型上没有 favoriteSpaceship 字段,所以这个查询是无效的:
1 | # 无效:favoriteSpaceship 不存在于 Character 之上 |
1 | { |
当我们查询一个字段时,如果其返回值不是标量或者枚举型,那我们就需要指明想要从这个字段中获取的数据。hero 返回 Character 类型,我们也请求了其中像是 name 和appearsIn 的字段;但如果将其省略,这个查询就变成无效的了:
1 | # 无效:hero 不是标量,需要指明下级字段 |
1 | { |
类似地,如果一个字段是标量,进一步查询它上面的字段也没有意义,这样做也会导致查询无效:
1 | # 无效:name 是标量,因此不允许下级字段查询 |
1 | { |
我们之前提到过,只有目标类型上的字段才可查询;当我们查询 hero 时,它会返回 Character,因此只有 Character 上的字段是可查询的。但如果我们要查的是 R2-D2 的 primary function 呢?
1 | # 无效:primaryFunction 不存在于 Character 之上 |
1 | { |
这个查询是无效的,因为 primaryFunction 并不是 Character 的字段。我们需要某种方法来表示:如果对应的 Character 是 Droid,我们希望获取 primaryFunction 字段,而在其他情况下,则忽略此字段。我们可以使用之前引入的“片段”来解决这个问题。先在 Droid 上定义一个片段,然后在查询中引入它,这样我们就能在定义了 primaryFunction 的地方查询它。
1 | { |
1 | { |
这个查询是有效的,但是有点琐碎;具名片段在我们需要多次使用的时候更有价值,如果只使用一次,那么我们应该使用内联片段而不是具名片段;这同样能表示我们想要查询的类型,而不用单独命名一个片段:
1 | { |
1 | { |
这只是验证系统的冰山一角;事实上需要一大套验证规则才能保证 GraphQL 查询的语义意义。规范中的“验证”章节有关于本话题更详细的内容,GraphQL.js 的 validation 目录包含了规范兼容的 GraphQL 验证器实现代码。
执行
一个 GraphQL 查询在被验证后,GraphQL 服务器会将之执行,并返回与请求的结构相对应的结果,该结果通常会是 JSON 的格式。
GraphQL 不能脱离类型系统处理查询,让我们用一个类型系统的例子来说明一个查询的执行过程,在这一系列的文章中我们重复使用了这些类型,下文是其中的一部分:
1 | type Query { |
现在让我们用一个例子来描述当一个查询请求被执行的全过程。
1 | { |
1 | { |
您可以将 GraphQL 查询中的每个字段视为返回子类型的父类型函数或方法。事实上,这正是 GraphQL 的工作原理。每个类型的每个字段都由一个 resolver 函数支持,该函数由 GraphQL 服务器开发人员提供。当一个字段被执行时,相应的 resolver 被调用以产生下一个值。
如果字段产生标量值,例如字符串或数字,则执行完成。如果一个字段产生一个对象,则该查询将继续执行该对象对应字段的解析器,直到生成标量值。GraphQL 查询始终以标量值结束。
根字段 & 解析器
每一个 GraphQL 服务端应用的顶层,必有一个类型代表着所有进入 GraphQL API 可能的入口点,我们将它称之为 Root 类型或 Query 类型。
在这个例子中查询类型提供了一个字段 human,并且接受一个参数 id。这个字段的解析器可能请求了数据库之后通过构造函数返回一个 Human 对象。
1 | Query: { |
这个例子使用了 JavaScript 语言,但 GraphQL 服务端应用可以被 多种语言实现。解析器函数接收 4 个参数:
obj上一级对象,如果字段属于根节点查询类型通常不会被使用。args可以提供在 GraphQL 查询中传入的参数。context会被提供给所有解析器,并且持有重要的上下文信息比如当前登入的用户或者数据库访问对象。info一个保存与当前查询相关的字段特定信息以及 schema 详细信息的值,更多详情请参考类型 GraphQLResolveInfo.
异步解析器
让我们来分析一下在这个解析器函数中发生了什么。
1 | human(obj, args, context, info) { |
context 提供了一个数据库访问对象,用来通过查询中传递的参数 id 来查询数据,因为从数据库拉取数据的过程是一个异步操作,该方法返回了一个 Promise 对象,在 JavaScript 语言中 Promise 对象用来处理异步操作,但在许多语言中存在相同的概念,通常称作 Futures、Tasks 或者 Defferred。当数据库返回查询结果,我们就能构造并返回一个新的 Human 对象。
这里要注意的是,只有解析器能感知到 Promise 的进度,GraphQL 查询只关注一个包含着 name 属性的 human 字段是否返回,在执行期间如果异步操作没有完成,则 GraphQL 会一直等待下去,因此在这个环节需要关注异步处理上的优化。
不重要的解析器
现在 Human 对象已经生成了,但 GraphQL 还是会继续递归执行下去。
1 | Human: { |
GraphQL 服务端应用的业务取决于类型系统的结构。在 human 对象返回值之前,由于类型系统确定了 human 字段将返回一个 Human 对象,GraphQL 会根据类型系统预设好的 Human 类型决定如何解析字段。
在这个例子中,对 name 字段的处理非常的清晰,name 字段对应的解析器被调用的时候,解析器回调函数的 obj 参数是由上层回调函数生成的 new Human 对象。在这个案例中,我们希望 Human 对象会拥有一个 name 属性可以让我们直接读取。
事实上,许多 GraphQL 库可以让你省略这些简单的解析器,假定一个字段没有提供解析器时,那么应该从上层返回对象中读取和返回和这个字段同名的属性。
标量强制
当 name 字段被处理后,appearsIn 和 starships 字段可以被同步执行, appearsIn 字段也可以有一个简单的解析器,但是让我们仔细看看。
1 | Human: { |
请注意,我们的类型系统声明 appearsIn 字段将返回具有已知值的枚举值,但是此函数返回数字!实际上,如果我们查看结果,我们将看到正在返回适当的枚举值。这是怎么回事?
这是一个强制标量的例子。因为类型系统已经被设定,所以解析器函数的返回值必须符合与类型系统对应的 API 规则的约束。在这个案例中,我们可能在服务器上定义了一个枚举类型,它在内部使用像是 4、5 和 6 这样的数字,但在 GraphQL 类型系统中将它们表示为枚举值。
列表解析器
我们已经看到一个字段返回上面的 appearsIn 字段的事物列表时会发生什么。它返回了枚举值的列表,因为这是系统期望的类型,列表中的每个项目被强制为适当的枚举值。让我们看下 startships 被解析的时候会发生什么?
1 | Human: { |
解析器在这个字段中不仅仅是返回了一个 Promise 对象,它返回一个 Promises 列表。Human 对象具有他们正在驾驶的 Starships 的 ids 列表,但是我们需要通过这些 id 来获得真正的 Starship 对象。
GraphQL 将并发执行这些 Promise,当执行结束返回一个对象列表后,它将继续并发加载列表中每个对象的 name 字段。
产生结果
当每个字段被解析时,结果被放置到键值映射中,字段名称(或别名)作为键值映射的键,解析器的值作为键值映射的值,这个过程从查询字段的底部叶子节点开始返回,直到根 Query 类型的起始节点。最后合并成为能够镜像到原始查询结构的结果,然后可以将其发送(通常为 JSON 格式)到请求的客户端。
让我们最后一眼看看原来的查询,看看这些解析函数如何产生一个结果:
1 | { |
1 | { |
内省
我们有时候会需要去问 GraphQL Schema 它支持哪些查询。GraphQL 通过内省系统让我们可以做到这点!
在我们的星战例子里,文件 starWarsIntrospection-test.js 包含了一系列展示了内省系统的查询,它也是一个测试文件,用来检验参考实现的内省系统。
如果是我们亲自设计了类型,那我们自然知道哪些类型是可用的。但如果类型不是我们设计的,我们也可以通过查询 __schema 字段来向 GraphQL 询问哪些类型是可用的。一个查询的根类型总是有 __schema 这个字段。现在来试试,查询一下有哪些可用的类型。
1 | { |
1 | { |
哇,有好多类型!它们都是什么?我们来总结一下:
- Query, Character, Human, Episode, Droid - 这些是我们在类型系统中定义的类型。
- String, Boolean - 这些是内建的标量,由类型系统提供。
- __Schema, __Type, __TypeKind, __Field, __InputValue, __EnumValue, __Directive - 这些有着两个下划线的类型是内省系统的一部分。
现在,来试试找到一个可以探索出有哪些可用查询的地方。当我们设计类型系统的时候,我们确定了一个所有查询开始的地方,来问问内省系统它是什么!
1 | { |
1 | { |
这和我们在类型系统那章里说的一样,Query 类型是我们开始的地方!注意这里的命名只是一个惯例,我们也可以把 Query 取成别的名字,只要我们把它定义为所有查询出发的地方,它也依然会在这里被返回。尽管如此,还是把它命名为 Query 吧,这是一个有用的惯例。
有时候也需要检验一个特定的类型。来看看 Droid 类型:
1 | { |
1 | { |
如果我们想要更了解 Droid 呢?例如,它是一个接口还是一个对象?
1 | { |
1 | { |
kind 返回一个枚举类型 __TypeKind,其中一个值是 OBJECT。如果我们改问 Character,我们会发现它是一个接口:
1 | { |
1 | { |
对于一个对象来说,知道它有哪些字段是很有用的,所以来问问内省系统 Droid 有哪些字段:
1 | { |
1 | { |
这些正是我们为 Droid 定义的字段!
id 看起来有点儿奇怪,这个类型没有名字。这是因为它是一个 NON_NULL 类型的“包装” 。如果我们请求它的 ofType 字段,我们会发现它是 ID ,告诉我们这是一个非空的 ID。
相似地,friends 和 appearsIn 都没有名字,因为它们都是 LIST 包装类型。我们可以看看它们的 ofType,就能知道它们是装什么东西的列表。
1 | { |
1 | { |
最后我们来看看内省系统特别适合用来开发工具的特性,我们来向内省系统请求文档!
1 | { |
1 | { |
因此我们可以通过内省系统接触到类型系统的文档,并做出文档浏览器,或是提供丰富的 IDE 体验。
这些只是内省系统的浅浅一层。我们还可以查询枚举值、某个类型实现了什么接口等等,我们甚至可以对内省系统内省。关于这个主题的详细说明可以看规范的“Introspection”部分,以及 GraphQL.js 中的 introspection 文件,它包含了符合规范的一个内省系统的实现。
最佳实践
介绍
GraphQL 最佳实践
GraphQL 规范特意忽略了一些面向 API 的重要问题,例如处理网络、授权和分页。这并不意味着在使用 GraphQL 时没有针对这些问题的解决方案,只是因为它们并非 GraphQL 定义中的一部分,可代以工程上通行的做法来实现。
本章节中的文章并非不可改动的真理,在某些情况下使用其他方式可能会更加合适。其中的一些文章介绍了 Facebook 在设计和部署 GraphQL 服务的过程中的一些开发理念,而另外一些则是为解决诸如提供 HTTP 服务和执行授权等常见问题提出了更多的策略建议。
以下内容是对 GraphQL 服务的一些常见的最佳实践和主观立场的简要说明,而本章节中的文章将对这些主题进行更深入的讨论。
HTTP
GraphQL 通常通过单入口来提供 HTTP 服务的完整功能,这一实现方式与暴露一组 URL 且每个 URL 只暴露一个资源的 REST API 不同。虽然 GraphQL 也可以暴露多个资源 URL 来使用,但这可能导致您在使用 GraphiQL 等工具时遇到困难。
了解更多:提供 HTTP 服务。
JSON(使用 GZIP 压缩)
GraphQL 服务通常返回 JSON 格式的数据,但 GraphQL 规范 并未要求这一点。对于期望更好的网络性能的 API 层来说,使用 JSON 似乎是一个奇怪的选择,但由于它主要是文本,因而在 GZIP 压缩后表现非常好。
推荐任何在生产环境下的 GraphQL 服务都启用 GZIP,并推荐在客户端请求头中加入:
1 | Accept-Encoding: gzip |
客户端和 API 开发人员也非常熟悉 JSON,易于阅读和调试。事实上,GraphQL 语法部分地受到 JSON 语法的启发。
版本控制
虽然没有什么可以阻止 GraphQL 服务像任何其他 REST API 一样进行版本控制,但 GraphQL 强烈认为可以通过 GraphQL schema 的持续演进来避免版本控制。
为什么大多数 API 有版本?当某个 API 入口能够返回的数据被限制,则任何更改都可以被视为一个破坏性变更,而破坏性变更需要发布一个新的版本。如果向 API 添加新功能需要新版本,那么在经常发布版本并拥有许多增量版本与保证 API 的可理解性和可维护性之间就需要权衡。
相比之下,GraphQL 只返回显式请求的数据,因此可以通过增加新类型和基于这些新类型的新字段添加新功能,而不会造成破坏性变更。这样可以衍生出始终避免破坏性变更并提供无版本 API 的通用做法。
可以为空的性质
大多数能够识别 “null” 的类型系统都提供普通类型和该类型可以为空的版本,默认情况下,类型不包括 “null”,除非明确声明。但在 GraphQL 类型系统中,默认情况下每个字段都可以为空。这是因为在由数据库和其他服务支持的联网服务中可能会出现许多问题,比如数据库可能会宕机,异步操作可能会失败,异常可能会被抛出。除了系统故障之外,授权通常可以是细粒度的,请求中的各个字段可以具有不同的授权规则。
通过默认设置每个字段可以为空,以上任何原因都可能导致该字段返回 “null”,而不是导致请求完全失败。作为替代,GraphQL 提供 non-null 这一变体类型来保证当客户端发出请求时,该字段永远不会返回 “null”。相反,如果发生错误,则上一个父级字段将为 “null”。
在设计 GraphQL schema 时,请务必考虑所有可能导致错误的情况下,“null” 是否可以作为获取失败的字段合理的返回值。通常它是,但偶尔,它不是。在这种情况下,请使用非空类型进行保证。
分页
GraphQL 类型系统允许某些字段返回 值的列表,但是为长列表分页的功能则交给 API 设计者自行实现。为 API 设计分页功能有很多种各有利弊的方案。
通常当字段返回长列表时,可以接收参数 “first” 和 “after” 来指定列表的特定区域,其中 “after” 是列表中每个值的唯一标识符。
最终在具有功能丰富的分页的 API 设计中,衍生出一种称为 “Connections” 的最佳实践模式。GraphQL 的一些客户端工具(如 Relay)采用了 Connections 模式,当 GraphQL API 使用此模式时,可以自动为客户端分页提供支持。
了解更多:分页。
服务器端的批处理与缓存
GraphQL 的设计方式便于您在服务器上编写整洁的代码,每种类型的每个字段都有一个专用且目标唯一的函数来解析该值。然而当考虑不完善时,一个过于简单的 GraphQL 服务可能会像 “聊天” 一样反复从您的数据库加载数据。
这通常可以通过批处理技术来解决,这一技术能够收集短时间内来自后端的多个数据请求,然后通过诸如 Facebook 的 DataLoader 等工具,将其打包成单个请求再发送到底层数据库或微服务。
关于 Graphs 的思考
一切皆是图 *
使用 GraphQL,你可以将你所有的业务建模为图
图是将很多真实世界现象变成模型的强大工具,因为它们和我们自然的心智模型和基本过程的口头描述很相似。通过 GraphQL,你会把自己的业务领域通过定义 schema 建模成一张图;在你的 schema 里,你定义不同类型的节点以及它们之间是如何连接的。在客户端这边,这创建了一种类似于面向对象编程的模式:引用其他类型的类型。在服务器端,由于 GraphQL 定义了接口,你可以在任何后端自由的使用它(无论新旧!)。
共同语言
命名是构建直观接口中一个困难但重要的部分
考虑下把你的 GraphQL schema 作为一种给你的团队和用户的沟通的共同语言。为了建立一个好的 schema,你必须检查你用来描述业务的日常语言。举个例子,让我们尝试用简单的文字描述一个电子邮件应用程序:
- 一个用户可以有多个邮箱账号
- 每个电子邮件帐户都有地址、收件箱、草稿箱、删除的邮件和发送的邮件
- 每封邮件都有发送人、接收日期、主题和正文
- 没有收件人地址,用户无法发送电子邮件
命名是构建直观的接口中一个困难但重要的部分,所以花时间仔细地考虑对于你的问题域和用户什么事有意义的。您的团队应该对这些业务领域的规则形成共同的理解和共识,因为您需要为 GraphQL schema 中的节点和关系选择直观,耐用的名称。试着去想象一些你想执行的查询:
获取我所有帐户的收件箱里未读邮件的数量
1 | { |
获取主账户的前二十封草稿邮件的“预览信息”
1 | { |
业务逻辑层
你的业务逻辑层应作为执行业务域规则的唯一正确来源
你应该在哪里定义真正的业务逻辑?你应该在哪里验证,检查用户权限?就是在专门的业务逻辑层里。你的业务逻辑层应作为执行业务域规则的唯一正确来源。
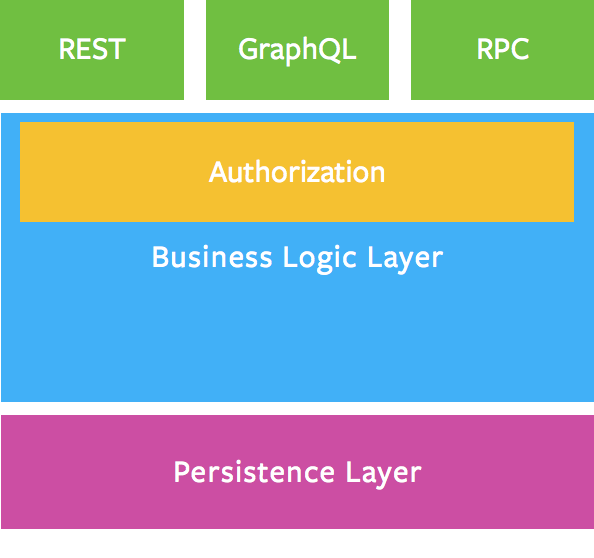
在上图中,系统中的所有入口点(REST、GraphQL和RPC)都将使用相同的验证、授权和错误处理规则进行处理。
使用旧有的数据
希望构建一个描述客户端如何使用数据的 GraphQL schema,而不是镜像旧有的数据库 schema。
有时候,你会发现自己正在使用不能完全反映客户端消费数据的旧有的数据源。在这种情况下,更倾向于构建一个描述客户端如何使用数据的 GraphQL schema,而不是镜像旧有的数据库 schema。
构建一个表达“是什么”而不是“怎么做”的 GraphQL schema。然后,您可以改进执行的具体细节,而不会破坏与旧客户端的接口。
一次一步
更频繁地进行验证和获得反馈
不要试图一次就做一个模型来构建整个业务域。 而是一次只构建一个场景所需的部分 schema。渐渐地拓展 schema,你要更频繁地进行验证和获得反馈,以便寻找到构建的正确解决方案。
通过 HTTP 提供服务
使用 GraphQL 时,最常见被选用的客户端到服务器协议是无处不在的 HTTP。以下是设置 GraphQL 服务器以通过 HTTP 进行操作的一些准则。
网络请求管道
大多数现代 Web 框架使用一个管道模型,通过一组中间件(也称为过滤器/插件)堆栈传递请求。当请求流经管道时,它可以被检查、转换、修改、或是返回响应并终止。GraphQL 应当被放置在所有身份验证中间件之后,以便你在 HTTP 入口端点处理器中能够访问到相同的会话和用户信息。
URI 和路由
HTTP 通常与 REST 相关联,REST 使用“资源”作为其核心概念。相比之下,GraphQL 的概念模型是一个实体图。因此,GraphQL 中的实体无法通过 URL 识别。相反,GraphQL 服务器在单个 URL /入口端点(通常是 /graphql)上运行,并且所有提供服务的 GraphQL 请求都应被导向此入口端点。
HTTP 方法、标题和正文
你的 GraphQL HTTP 服务器应当能够处理 HTTP GET 和 POST 方法。
GET 请求
在收到一个 HTTP GET 请求时,应当在 “query” 查询字符串(query string)中指定 GraphQL 查询。例如,如果我们要执行以下 GraphQL 查询:
1 | { |
此请求可以通过 HTTP GET 发送,如下所示:
1 | http://myapi/graphql?query={me{name}} |
查询变量可以作为 JSON 编码的字符串发送到名为 variables 的附加查询参数中。如果查询包含多个具名操作,则可以使用一个 operationName 查询参数来控制哪一个应当执行。
POST 请求
标准的 GraphQL POST 请求应当使用 application/json 内容类型(content type),并包含以下形式 JSON 编码的请求体:
1 | { |
operationName 和 variables 是可选字段。仅当查询中存在多个操作时才需要 operationName。
除了上边这种请求之外,我们还建议支持另外两种情况:
- 如果存在 “query” 这一查询字符串参数(如上面的 GET 示例中),则应当以与 HTTP GET 相同的方式进行解析和处理。
- 如果存在 “application/graphql” Content-Type 头,则将 HTTP POST 请求体内容视为 GraphQL 查询字符串。
如果你使用的是 express-graphql,那么你已经直接获得了这些支持。
响应
无论使用任何方法发送查询和变量,响应都应当以 JSON 格式在请求正文中返回。如规范中所述,查询结果可能会是一些数据和一些错误,并且应当用以下形式的 JSON 对象返回:
1 | { |
如果没有返回错误,响应中不应当出现 "errors" 字段。如果没有返回数据,则 根据 GraphQL 规范,只能在执行期间发生错误时才能包含 "data" 字段。
GraphiQL
GraphiQL 在测试和开发过程中非常有用,但在生产环境下应当默认被禁用。如果你使用的是 express-graphql,可以根据 NODE_ENV 环境变量进行切换:
1 | app.use('/graphql', graphqlHTTP({ |
Node
如果你正在使用 NodeJS,我们推荐使用 express-graphql 或 graphql-server。
授权
将授权逻辑委托给业务逻辑层
授权是一种业务逻辑,描述给定的用户、会话、上下文是否具有执行操作的权限或查看一条数据的权限。例如:
“只有作者才能看到他们自己的草稿”
应当在 业务逻辑层 实施这种行为。在 GraphQL 层中放置授权逻辑是很吸引人的,如下所示:
1 | var postType = new GraphQLObjectType({ |
可以看到我们通过检查帖子的 authorId 字段是否等于当前用户的 id 来定义“作者拥有一个帖子”。你能发现其中的问题吗?我们需要复制这段代码到服务中的每一个入口端点。一旦我们无法保证授权逻辑的完全同步,用户可能在使用不同的 API 时看到不同的数据。我们可以通过确定授权的 唯一真实来源 来避免这种情况。
在学习 GraphQL 或原型设计时,在解析器内定义授权逻辑是可以接受的。然而,对于生产代码库来说,还是将授权逻辑委托给业务逻辑层。这里有一个例子:
1 | // 授权逻辑在 postRepository 中 |
在上面的例子中,我们看到业务逻辑层要求调用者提供一个用户对象。如果您使用 GraphQL.js,您应当在解析器的 context 参数或是第四个参数中的 rootValue 上填充 User 对象。
我们建议将完全混合 [1] 的 User 对象传递给业务逻辑层,而非传递不透明的 token 或 API 密钥。这样,我们可以在请求处理管道的不同阶段处理 身份验证 和授权的不同问题。
- “混合(hydrated)”一个对象是指:对一个存储在内存中且尚未包含任何域数据(“真实”数据)的对象,使用域数据(例如来自数据库、网络或文件系统的数据)进行填充。 *
分页
不同的分页模型可以实现不同的客户端功能
在 GraphQL 中一个常见的用例是遍历对象集合之间的关系。在 GraphQL 中有许多不同的方式来展示这些关系,为客户端开发人员提供了一组不同的功能。
复数
暴露对象之间连接的最简单方法是返回一个复数类型的字段。例如,如果我们想得到一个 R2-D2 的朋友列表,我们可以直接请求所有的朋友:
1 | { |
切片
但是,尽管如此,我们也意识到客户端可能需要其他行为。客户可能希望能够指定他们想要获取的朋友数量;也许他们只要前两个。所以我们想要暴露一些类似的东西:
1 | { |
但即使我们仅仅获得前两个结果,我们可能仍然想要在列表中分页:一旦客户端获取前两个朋友,他们可能会发送第二个请求来请求接下来的两个朋友。我们如何启用这个行为?
分页和边
我们有很多种方法来实现分页:
- 我们可以像这样
friends(first:2 offset:2)来请求列表中接下来的两个结果。 - 我们可以像这样
friends(first:2 after:$friendId), 来请求我们上一次获取到的最后一个朋友之后的两个结果。 - 我们可以像这样
friends(first:2 after:$friendCursor), 从最后一项中获取一个游标并使用它来分页。
一般来说,我们发现基于游标的分页是最强大的分页。特别当游标是不透明的时,则可以使用基于游标的分页(通过为游标设置偏移或 ID)来实现基于偏移或基于 ID 的分页,并且如果分页模型在将来发生变化,则使用游标可以提供额外的灵活性。需要提醒的是,游标是不透明的,并且它们的格式不应该被依赖,我们建议用 base64 编码它们。
这导致我们遇到一个问题:我们如何从对象中获取游标?我们不希望游标放置在 User 类型上;它是连接的属性,而不是对象的属性。所以我们可能想要引入一个新的间接层;我们的 friends 字段应该给我们一个边(edge)的列表,边同时具有游标和底层节点:
1 | { |
如果存在针对于边而不是针对于某一个对象的信息,则边这个概念也被证明是有用的。例如,如果我们想要在 API 中暴露“友谊时间”,将其放置在边里是很自然的。
列表的结尾、计数以及连接
现在我们有能力使用游标对连接进行分页,但是我们如何知道何时到达连接的结尾?我们必须继续查询,直到我们收到一个空列表,但是我们真的希望连接能够告诉我们什么时候到达结尾,这样我们不需要额外的请求。同样的,如果我们想知道关于连接本身的附加信息怎么办;例如,R2-D2 有多少个朋友?
为了解决这两个问题,我们的 friends 字段可以返回一个连接对象。连接对象将拥有一个存放边的字段以及其他信息(如总计数和有关下一页是否存在的信息)。所以我们的最终查询可能看起来像这样:
1 | { |
请注意,我们也可能在这个 PageInfo 对象中包含 endCursor 和 startCursor。这样,如果我们不需要边所包含的任何附加信息,我们就不需要查询边,因为我们从 pageInfo 获取了分页所需的游标。这导致连接的潜在可用性改进;相比于仅暴露 edges 列表,我们还可以暴露一个仅包含节点的专用列表,以避免使用间接层。
完整的连接模型
显然,这比我们原来只有复数的设计更复杂!但是通过采用这种设计,我们已经为客户解锁了许多功能:
- 为列表分页的能力。
- 请求有关连接本身的信息的能力,如
totalCount或pageInfo。 - 请求有关边本身的信息的能力,如
cursor或friendshipTime。 - 改变我们后端如何实现分页的能力,因为用户仅使用不透明的游标。
要查看此操作,在示例 schema 中有一个附加字段,称为 friendsConnection,它暴露了所有这些概念。你可以在示例查询中查看它。尝试将 after 参数从 friendsConnection 移除以查看分页如何受到影响。另外,尝试用连接上的 friends 辅助字段替换 edges 字段,当适用于客户端时,这样可以直接访问朋友列表而无需额外的边这一层。
1 | { |
1 | { |
连接规范
为了确保该模式的一致实现,Relay 项目具有正式的规范,你可以遵循该规范来构建使用基于游标的连接模式的 GraphQL API。
全局对象识别
一致的对象访问实现了简单的缓存和对象查找
为了提供给 GraphQL 客户端选项以优雅地处理缓存和数据重新获取,GraphQL 服务端需要以标准化的方式公开对象标识符。
为此客户端需要通过以 ID 请求对象的标准机制进行查询。然后在响应中,schema 将需要提供一种提供这些 ID 的标准方式。
因为除了 ID 之外,对对象知之甚少,所以我们称它们为对象“节点”。这是一个查询节点的示例:
1 | { |
- GraphQL schema 的格式允许通过根查询对象上的
node字段获取任何对象。返回的对象符合 “Node” 接口。 - 可以安全地从响应中提取出
id字段,并可以通过缓存和重新获取将其存储以供重用。 - 客户端可以使用接口片段来提取特定于类型的、符合节点接口的其他信息。在本示例中为 “User”。
Node 接口如下:
1 | # 具有全局唯一 ID 的对象 |
User 通过以下方式符合接口:
1 | type User implements Node { |
规范
下面的所有内容以更加正式的要求描述了围绕对象标识的规范,以确保在服务端实现之间的一致性。 这些规范是基于服务端如何与 Relay API 客户端兼容来写的,但是对任何客户端都有用。
保留类型
与此规范兼容的 GraphQL 服务端必须保留某些类型和类型名称,以支持一致的对象标识模型。特别地,此规范为以下类型创建了准则:
- 一个名为
Node的接口。 - 根查询类型上的
node字段。
Node 接口
服务端必须提供一个名为 Node 的接口。该接口必须有且仅有一个名为 id 的字段,该字段返回非空的 ID。
这个 id 应当是该对象的全局唯一标识符,并且只要给出这个 id,服务端就应该能够重新获取该对象。
内省
正确实现上述接口的服务端将接受如下的内省查询,并返回提供的响应:
1 | { |
返回
1 | { |
Node 根字段
服务端必须提供一个名为 node,且返回 Node 接口的根字段。该根字段必须有且仅有一个参数,即名为 id 的非空ID。
如果一个查询返回的对象实现了 Node,那么当服务端在 Node 的 id 字段中返回的值作为 id 参数传递给 node 的根字段时,该根字段应该重新获取相同的对象。
服务端必须尽最大努力来获取此数据,但并非总能成功。例如,服务端可能会返回一个带有有效 id 的 User,但是当发出使用 node 根字段重新获取该用户的请求时,该用户的数据库可能不可用,或者该用户可能已删除了他的 帐户。在这种情况下,查询该字段的结果应为 null。
内省
正确实现上述需求的服务端将接受如下的内省查询,并返回包含所提供响应的响应:
1 | { |
返回
1 | { |
字段稳定性
如果一个查询中出现两个对象,并且都使用相同的ID来实现 Node,则这两个对象必须相等。
出于此定义的目的,对象相等性定义如下:
- 如果在两个对象上都查询了一个字段,则在第一个对象上查询该字段的结果必须等于在第二个对象上查询该字段的结果。
- 如果该字段返回一个标量,则相等性定义为该标量的相等性。
- 如果该字段返回一个枚举,则相等性定义为两个字段都返回相同的枚举值。
- 如果该字段返回一个对象,则按照上述方法递归定义相等性。
例如:
1 | { |
可能会返回:
1 | { |
由于 fourNode.id 与 fiveNode.userWithIdOneLess.id 相同,我们可以通过上述条件保证 fourNode.name 必须与 fiveNode.userWithIdOneLess.name 相同,并且确实如此。
复数识别根字段
想象一下一个名为 username 的根字段,该根字段使用用户的用户名为参数并返回对应的用户:
1 | { |
可能会返回:
1 | { |
显然,我们可以将响应中的对象(ID 为 4 的用户)与请求链接起来,以用户名 “zuck” 识别对象。现在想象一下一个名为 usernames 的根字段,它包含一个用户名列表并返回一个对象列表:
1 | { |
可能会返回:
1 | { |
为了使客户端能够将用户名链接到响应,它需要知道响应中的数组将与作为参数传递的数组大小相同,并且响应中的顺序将与参数中的顺序匹配。我们称这些为复数识别根字段,其要求如下所述。
字段
符合此规范的服务端可能会公开接受输入参数列表的根字段,并返回响应列表。为了使符合规范的客户端使用这些字段,这些字段必须是复数识别根字段,并且必须满足以下要求。
注意:符合规范的服务端也可能会公开不是复数识别根字段的根字段。符合规范的客户端将无法在其查询中将这些字段用作根字段。
复数识别根字段必须有且仅有一个参数。该参数的类型必须是非空的非空值列表。在我们的 usernames 示例中,该字段将使用名为 usernames 的单一参数,其类型(使用我们的类型系统速记)将为 [String!]!。
复数识别根字段的返回类型必须是列表,或者包含一个列表的非空包装器。该列表必须包装 Node 接口,一个实现 Node 接口的对象或是包含这些类型的非空包装器。
每当使用复数识别根字段时,响应中列表的长度必须与参数中列表的长度相同。响应中的每个项目都必须与输入中的项目相对应。 更正式地来说,如果传递给根字段一个输入列表 Lin 使得输出值为 Lout,那么对于任意置换 P,传递根字段 P(Lin) 必须使得输出值为 P(Lout)。
因此,建议服务端不要将为响应类型添加非空包装器,因为如果无法为输入中的给定条目获取对象,它仍然必须在输出中为该输入条目提供一个值;对这种情况来说 null 是一个有用的值。
缓存
提供对象的标识符以便客户端构建丰富的缓存
在基于入口端点的 API 中,客户端可以使用 HTTP 缓存来确定两个资源是否相同,从而轻松避免重新获取资源。这些 API 中的 URL 是全局唯一标识符,客户端可以利用它来构建缓存。然而,在 GraphQL 中,没有类似 URL 的基元能够为给定对象提供全局唯一标识符。这里提供为 API 暴露这种标识符以供客户端使用的最佳实践。
全局唯一 ID
一个可行的模式是将一个字段(如 id)保留为全局唯一标识符。这些文档中使用的示例模式使用此方法:
1 | { |
1 | { |
这是向客户端开发人员提供的强大工具。与基于资源的 API 使用 URL 作为全局唯一主键的方式相同,该系统中提供 id 字段作为全局唯一主键。
如果后端使用类似 UUID 的标识符,那么暴露这个全局唯一 ID 可能非常简单!如果后端对于每个对象并未分配全局唯一 ID,则 GraphQL 层可能需要构造此 ID。通常来说,将类型的名称附加到 ID 并将其用作标识符都很简单;服务器可能会通过 base64 编码使该 ID 不透明。
可选地,此 ID 之后可以和 全局对象标识 的 node 模式一起使用。
与现有 API 的兼容
为了这一目的而使用 id 字段的一个问题是如何让使用 GraphQL API 的客户端能够与现有的 API 并存。例如,如果我们现有的 API 接受了特定类型的 ID,但是我们的 GraphQL API 使用了全局唯一 ID,那么同时使用两者可能比较棘手。
在这些情况下,GraphQL API 可以在单独的字段中暴露以前的 API 的 ID。这同时带给我们两方面的好处:
- GraphQL 客户端可以继续依靠一致的机制来获取全局唯一 ID。
- 当客户端需要使用我们以前的 API 时也可以从对象中获取
previousApiId并使用它。
备选方案
虽然全局唯一 ID 在过去已经被证明是一种强大的模式,但它们并不是唯一可以使用的模式,也不适用于每种情况。客户端需要的真正关键功能是为其缓存导出全局唯一标识符的能力。服务器可以导出此 ID 以简化客户端,而客户端同样也可以导出标识符。通常,将对象的类型(通过 __typename 查询)与某些类型唯一标识符相结合就很简单。
另外,如果使用 GraphQL API 替换现有的 API,那么如果 GraphQL 中的其他所有字段都相同,只更换了全局唯一的 id,这可能会令人困惑。这可能是为什么不选用 id 作为全局唯一字段的另一个原因。


