Redis集群环境搭建实践
redis v6.2.5
ubuntu 20.04
Redis集群(Redis Cluster) 是Redis提供的分布式数据库方案,通过 分片(sharding) 来进行数据共享,并提供复制和故障转移功能。相比于主从复制、哨兵模式,Redis集群实现了较为完善的高可用方案,解决了存储能力受到单机限制,写操作无法负载均衡的问题。
编译安装 1 2 3 4 5 6 cd /opt wget http://download.redis.io/releases/redis-6.2.5.tar.gz tar -xvf redis-6.2.5.tar.gz cd redis-6.2.5 make MALLOC=libc make install PREFIX=/usr/local/redis
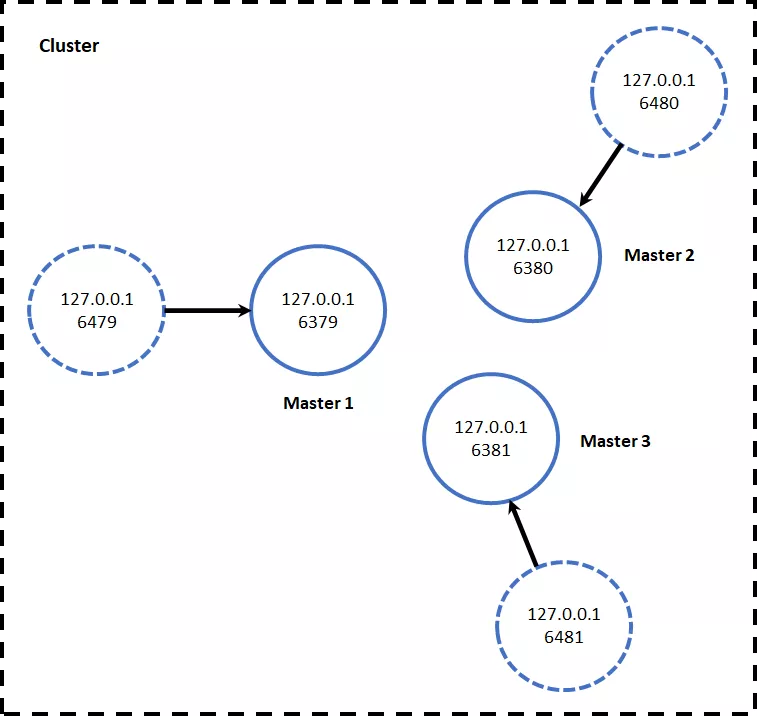
集群环境搭建 方便起见,这里集群环境的所有节点全部位于同一个服务器上,共6个节点以端口号区分,3个主节点+3个从节点。集群的简单架构如图:
集群的搭建可以分为四步:
启动节点:将节点以集群方式启动,此时节点是独立的。
节点握手:将独立的节点连成网络。
槽指派:将16384个槽位分配给主节点,以达到分片保存数据库键值对的效果。
主从复制:为从节点指定主节点。
启动节点 创建集群目录
1 2 3 4 5 6 mkdir /usr/local/redis/cluster cd /usr/local/redis/cluster mkdir run log data mkdir 700{0,1,2,3,4,5} cd data mkdir 700{0,1,2,3,4,5}
拷贝执行文件
1 2 3 cp -a /usr/local/redis/bin/* /usr/local/redis/cluster/7000/ cp -a /opt/redis-6.2.5/redis.conf /usr/local/redis/cluster/7000/ cd /usr/local/redis/cluster/7000/
修改配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 vi /usr/local/redis/cluster/7000/redis.conf # 添加本机的ip bind 172.16.5.8 # 端口 port 7000 # pid存储目录 pidfile /usr/local/redis/cluster/run/redis_7000.pid # 日志存储目录 logfile /usr/local/redis/cluster/log/redis_7000.log # 数据存储目录,目录要提前创建好 dir /usr/local/redis/cluster/data/7000 # 开启集群 cluster-enabled yes # 集群节点配置文件,这个文件是不能手动编辑的。确保每一个集群节点的配置文件不通 cluster-config-file nodes-7000.conf # 集群节点的超时时间,单位:ms,超时后集群会认为该节点失败 cluster-node-timeout 15000 # 持久化文件 dbfilename "dump-7000.rdb" # 持久化 appendonly yes # 守护进程 daemonize yes
将7000目录下的文件拷贝到7001~7005目录中,并修改redis.conf,替换配置文件中的7000, sed 's/7000/7001/g' ./7000/redis.conf > ./7001/redis.conf
启动集群脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 cd /usr/local/redis/cluster vi start-cluster.sh chmod +x start-cluster.sh cd 7000 ./redis-server redis.conf cd .. cd 7001 ./redis-server redis.conf cd .. cd 7002 ./redis-server redis.conf cd .. cd 7003 ./redis-server redis.conf cd .. cd 7004 ./redis-server redis.conf cd .. cd 7005 ./redis-server redis.conf cd ..
1 2 3 4 5 6 7 8 9 10 11 12 13 # !/bin/bash # create nodes array nodes=(7000 7001 7002 7003 7004 7005) for node in ${nodes[@]} do ./redis-server /opt/redis/redis-5.0.7/cluster-config/redis-${node}.conf if [ $? = 0 ]; then echo "port $node start success !"; else echo " port $node start fail "; fi done exit 0
关闭集群脚本
1 2 3 4 vi stop-cluster.sh chmod +x stop-cluster.sh pgrep redis-server | xargs -exec kill -9
启动集群
1 2 3 4 5 6 7 8 9 10 ./start-cluster.sh ps -aux | grep redis root@ubuntu:/usr/local/redis/cluster# ps -aux | grep redis root 5024 0.0 0.0 37252 3752 ? Ssl 17:31 0:00 ./redis-server 172.16.5.8:7000 [cluster] root 5029 0.0 0.0 37252 3804 ? Ssl 17:31 0:00 ./redis-server 172.16.5.8:7001 [cluster] root 5034 0.0 0.0 37252 3672 ? Ssl 17:31 0:00 ./redis-server 172.16.5.8:7002 [cluster] root 5039 0.0 0.0 37252 3760 ? Ssl 17:31 0:00 ./redis-server 172.16.5.8:7003 [cluster] root 5044 0.0 0.0 37252 3748 ? Ssl 17:31 0:00 ./redis-server 172.16.5.8:7004 [cluster] root 5049 0.0 0.0 37252 3744 ? Ssl 17:31 0:00 ./redis-server 172.16.5.8:7005 [cluster]
节点握手 每个节点启动后,节点间是相互独立的,他们都处于一个只包含自己的集群当中,以端口号6379的服务器为例,利用 CLUSTER NODES 查看当前集群包含的节点。
1 2 3 ./redis-cli -h 172.16.5.8 -p 7000 172.16.5.8:7000> CLUSTER NODES f039edd523b1b2fe79589edc693e7701454cf83f :7000@17000 myself,master - 0 0 0 connected
我们需要将各个独立的节点连接起来,构成一个包含多个节点的集群,使用 CLUSTER MEET 命令。
1 2 3 4 5 6 7 8 9 10 11 ./redis-cli -h 172.16.5.8 -p 7000 -c # -c 选项指定以Cluster模式运行redis-cli 172.16.5.8:7000> CLUSTER MEET 172.16.5.8 7001 OK 172.16.5.8:7000> CLUSTER MEET 172.16.5.8 7002 OK 172.16.5.8:7000> CLUSTER MEET 172.16.5.8 7003 OK 172.16.5.8:7000> CLUSTER MEET 172.16.5.8 7004 OK 172.16.5.8:7000> CLUSTER MEET 172.16.5.8 7005 OK
再次查看此时集群中包含的节点情况
1 2 3 4 5 6 7 172.16.5.8:7000> CLUSTER NODES f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,master - 0 1632735762000 0 connected 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632735760061 1 connected 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632735759000 3 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 master - 0 1632735761000 5 connected 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 master - 0 1632735762086 4 connected 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632735761080 2 connected
可以发现此时6个节点均作为主节点加入到集群中, CLUSTER NODES 返回的结果各项含义如下:
1 <id> <ip:port@cport> <flags> <master> <ping-sent> <pong-recv> <config-epoch> <link-state> <slot> <slot> ... <slot>
节点id: 由40个16进制字符串组成,节点id只在集群初始化时创建一次,然后保存到集群配置文件(即前文提到的cluster-config-file)中,以后节点重新启动时会直接在集群配置文件中读取。
port@cport: 前者为普通端口,用于为客户端提供服务;后者为集群端口,分配方法为:普通端口+10000,只用于节点间的通讯。
其余各项的详细解释可以参考官方文档cluster nodes。
槽指派 Redis集群通过分片(sharding)的方式保存数据库的键值对,整个数据库被分为16384个槽(slot),数据库每个键都属于这16384个槽的一个,集群中的每个节点都可以处理0个或者最多16384个slot。
槽是数据管理和迁移的基本单位。当数据库中的16384个槽都分配了节点时,集群处于上线状态(ok);如果有任意一个槽没有分配节点,则集群处于下线状态(fail)。
注意,只有主节点有处理槽的能力,如果将槽指派步骤放在主从复制之后,并且将槽位分配给从节点,那么集群将无法正常工作(处于下线状态)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ./redis-cli -h 172.16.5.8 -p 7000 cluster addslots {0..5000} ./redis-cli -h 172.16.5.8 -p 7001 cluster addslots {5001..10000} ./redis-cli -h 172.16.5.8 -p 7002 cluster addslots {10001..16383} ./redis-cli -h 172.16.5.8 -p 7000 -c 172.16.5.8:7000> CLUSTER NODES f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,master - 0 1632736198000 0 connected 0-5000 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632736197000 1 connected 5001-10000 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632736196606 3 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 master - 0 1632736197613 5 connected 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 master - 0 1632736199630 4 connected 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632736198620 2 connected 10001-16383 172.16.5.8:7000> CLUSTER INFO cluster_state:ok # 集群处于上线状态 cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:5 cluster_my_epoch:0 cluster_stats_messages_ping_sent:616 cluster_stats_messages_pong_sent:607 cluster_stats_messages_meet_sent:5 cluster_stats_messages_sent:1228 cluster_stats_messages_ping_received:607 cluster_stats_messages_pong_received:621 cluster_stats_messages_received:1228
主从复制 集群节点均作为主节点存在,仍不能实现Redis的高可用,配置主从复制之后,才算真正实现了集群的高可用功能。 用来让集群中接收命令的节点成为 node_id 所指定节点的从节点,并开始对主节点进行复制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 7000(主) ==> 7003(从) # 7001(主) ==> 7004(从) # 7002(主) ==> 7005(从) ./redis-cli -h 172.16.5.8 -p 7003 cluster replicate f039edd523b1b2fe79589edc693e7701454cf83f ./redis-cli -h 172.16.5.8 -p 7004 cluster replicate 74fcaf33e74e0b537be4e539edbd075ba7462334 ./redis-cli -h 172.16.5.8 -p 7005 cluster replicate 0431cb8079fb3b9fb1df687ff4472d83f003eb38 ./redis-cli -h 172.16.5.8 -p 7000 -c 172.16.5.8:7000> CLUSTER NODES f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,master - 0 1632737582000 0 connected 0-5000 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632737580882 1 connected 5001-10000 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 slave f039edd523b1b2fe79589edc693e7701454cf83f 0 1632737581891 0 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 slave 74fcaf33e74e0b537be4e539edbd075ba7462334 0 1632737581000 1 connected 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 slave 0431cb8079fb3b9fb1df687ff4472d83f003eb38 0 1632737582899 2 connected 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632737579876 2 connected 10001-16383
备注:以上的步骤可以用redis-cli --cluster create命令来一步到位。在Redis 5.0之前利用redis-trib.rb工具实现,之后直接利用redis-cli完成,参考命令如下:
1 2 # --cluster-replicas 1 指示给定的创建节点列表是以主节点+从节点对组成的。 redis-cli --cluster create 172.16.5.8:7000 172.16.5.8:7001 172.16.5.8:7002 172.16.5.8:7003 172.16.5.8:7004 172.16.5.8:7005 --cluster-replicas 1
集群中执行命令 集群此时处于上线状态,可以通过客户端向集群中的节点发送命令。接收命令的节点会计算出命令要处理的键属于哪个槽,并检查这个槽是否指派给自己。
如果键所在的slot刚好指派给了当前节点,会直接执行这个命令。
否则,节点向客户端返回 MOVED 错误,指引客户端转向 redirect 至正确的节点,并再次发送此前的命令。
此处,我们利用 CLUSTER KEYSLOT 查看到键 name 所在槽号为5798(被分配在7001节点),当对此键操作时,会被重定向到相应的节点。对键 fruits 的操作与此类似。
1 2 3 4 5 6 7 8 9 10 11 172.16.5.8:7000> CLUSTER KEYSLOT name (integer) 5798 172.16.5.8:7000> set name huey -> Redirected to slot [5798] located at 172.16.5.8:7001 OK 172.16.5.8:7001> 172.16.5.8:7000> get fruits -> Redirected to slot [14943] located at 172.16.5.8:7002 (nil) 172.16.5.8:7002>
值得注意的是,当我们将命令通过客户端发送给一个从节点时,命令会被重定向至对应的主节点。
1 2 3 4 5 6 172.16.5.8:7001> KEYS * 1) "name" 172.16.5.8:7001> get fruits -> Redirected to slot [14943] located at 172.16.5.8:7002 (nil) 172.16.5.8:7002>
集群故障转移 集群中主节点下线时,复制此主节点的所有的从节点将会选出一个节点作为新的主节点,并完成故障转移。和主从复制的配置相似,当原先的从节点再次上线,它会被作为新主节点的的从节点存在于集群中。
下面模拟7000节点宕机的情况(将其SHUTDOWN),可以观察到其从节点7003将作为新的主节点继续工作。
1 2 3 4 5 6 7 8 9 10 11 12 13 172.16.5.8:7001> SHUTDOWN less /usr/local/redis/cluster/log/redis_7003.log 5039:S 27 Sep 2021 18:27:25.749 * FAIL message received from 560242d50f63ebb5f349791893ed2094cb2939bd about f039edd523b1b2fe79589edc693e7701454cf83f 5039:S 27 Sep 2021 18:27:25.749 # Cluster state changed: fail 5039:S 27 Sep 2021 18:27:25.847 # Start of election delayed for 534 milliseconds (rank #0, offset 1246). 5039:S 27 Sep 2021 18:27:26.452 # Starting a failover election for epoch 6. 5039:S 27 Sep 2021 18:27:26.454 # Failover election won: I'm the new master. 5039:S 27 Sep 2021 18:27:26.454 # configEpoch set to 6 after successful failover 5039:M 27 Sep 2021 18:27:26.454 * Discarding previously cached master state. 5039:M 27 Sep 2021 18:27:26.454 # Setting secondary replication ID to 519b9ab3c0f125d5e5738ee051b8d34943a8fd33, valid up to offset: 1247. New replication ID is 601c0afefa909a479ca1e5e70ead3995322d9a38 5039:M 27 Sep 2021 18:27:26.454 # Cluster state changed: ok
7000节点从宕机状态恢复后,将作为7003节点的从节点存在。
1 2 3 4 5 6 7 8 ./redis-cli -h 172.16.5.8 -p 7000 -c 172.16.5.8:7000> CLUSTER NODES 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 slave 0431cb8079fb3b9fb1df687ff4472d83f003eb38 0 1632738661714 2 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 slave 74fcaf33e74e0b537be4e539edbd075ba7462334 0 1632738659696 1 connected f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,slave 9e904f9593f05854440cbc16623bdf30abbbf6f5 0 1632738658000 6 connected 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632738660703 6 connected 0-5000 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632738661000 1 connected 5001-10000 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632738660000 2 connected 10001-16383
前文提到cluster-config-file会记录下集群节点的状态,打开节点7000的配置文件nodes-7000.conf,可以看到 CLUSTER NODES 所示信息均被保存在配置文件中:
1 2 3 4 5 6 7 8 9 less /usr/local/redis/cluster/data/7000/nodes-7000.conf 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 slave 0431cb8079fb3b9fb1df687ff4472d83f003eb38 0 1632738653750 2 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 slave 74fcaf33e74e0b537be4e539edbd075ba7462334 0 1632738653750 1 connected f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,slave 9e904f9593f05854440cbc16623bdf30abbbf6f5 0 1632738653748 6 connected 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632738653750 6 connected 0-5000 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632738653750 1 connected 5001-10000 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632738653750 2 connected 10001-16383 vars currentEpoch 6 lastVoteEpoch 0
集群伸缩实践 集群伸缩的关键在于对集群的进行重新分片,实现槽位在节点间的迁移。本节将以在集群中添加节点和删除节点为例,对槽迁移进行实践。
借助于redis-cli中集成的redis-trib.rb工具进行槽位的管理,工具的帮助菜单如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 redis-cli --cluster help Cluster Manager Commands: create host1:port1 ... hostN:portN --cluster-replicas <arg> check host:port --cluster-search-multiple-owners info host:port fix host:port --cluster-search-multiple-owners --cluster-fix-with-unreachable-masters reshard host:port --cluster-from <arg> --cluster-to <arg> --cluster-slots <arg> --cluster-yes --cluster-timeout <arg> --cluster-pipeline <arg> --cluster-replace rebalance host:port --cluster-weight <node1=w1...nodeN=wN> --cluster-use-empty-masters --cluster-timeout <arg> --cluster-simulate --cluster-pipeline <arg> --cluster-threshold <arg> --cluster-replace add-node new_host:new_port existing_host:existing_port --cluster-slave --cluster-master-id <arg> del-node host:port node_id call host:port command arg arg .. arg --cluster-only-masters --cluster-only-replicas set-timeout host:port milliseconds import host:port --cluster-from <arg> --cluster-from-user <arg> --cluster-from-pass <arg> --cluster-from-askpass --cluster-copy --cluster-replace backup host:port backup_directory help For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster. Cluster Manager Options: --cluster-yes Automatic yes to cluster commands prompts
添加节点 考虑在集群中添加两个节点,端口号为7006和7007,其中节点7006为主节点,7007为从节点。
(2) 节点握手:借助 redis-cli --cluster add-node 命令分别添加节点7006和7007。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 redis-cli --cluster add-node 172.16.5.8:7006 172.16.5.8:7000 > >> Adding node 172.16.5.8:7006 to cluster 172.16.5.8:7000 > >> Performing Cluster Check (using node 172.16.5.8:7000) S: f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000 slots: (0 slots) slave replicates 9e904f9593f05854440cbc16623bdf30abbbf6f5 M: 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001 slots:[5001-10000] (5000 slots) master 1 additional replica(s) S: 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005 slots: (0 slots) slave replicates 0431cb8079fb3b9fb1df687ff4472d83f003eb38 S: 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004 slots: (0 slots) slave replicates 74fcaf33e74e0b537be4e539edbd075ba7462334 M: 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003 slots:[0-5000] (5001 slots) master 1 additional replica(s) M: 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002 slots:[10001-16383] (6383 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. > >> Check for open slots... > >> Check slots coverage... [OK] All 16384 slots covered. > >> Send CLUSTER MEET to node 172.16.5.8:7006 to make it join the cluster. [OK] New node added correctly. redis-cli --cluster add-node 172.16.5.8:7007 172.16.5.8:7000 > >> Adding node 172.16.5.8:7007 to cluster 172.16.5.8:7000 > >> Performing Cluster Check (using node 172.16.5.8:7000) S: f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000 slots: (0 slots) slave replicates 9e904f9593f05854440cbc16623bdf30abbbf6f5 M: 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001 slots:[5001-10000] (5000 slots) master 1 additional replica(s) M: b4e28457008108d23ba30c0ae4b03034c7d6830f 172.16.5.8:7006 slots: (0 slots) master S: 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005 slots: (0 slots) slave replicates 0431cb8079fb3b9fb1df687ff4472d83f003eb38 S: 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004 slots: (0 slots) slave replicates 74fcaf33e74e0b537be4e539edbd075ba7462334 M: 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003 slots:[0-5000] (5001 slots) master 1 additional replica(s) M: 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002 slots:[10001-16383] (6383 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. > >> Check for open slots... > >> Check slots coverage... [OK] All 16384 slots covered. > >> Send CLUSTER MEET to node 172.16.5.8:7007 to make it join the cluster. [OK] New node added correctly. 172.16.5.8:7000> CLUSTER NODES 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632791095242 1 connected 5001-10000 b4e28457008108d23ba30c0ae4b03034c7d6830f 172.16.5.8:7006@17006 master - 0 1632791092000 7 connected c5290e4bd86416fc6cf6ddbbd98ef7acd0f4b5df 172.16.5.8:7007@17007 master - 0 1632791093218 0 connected f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,slave 9e904f9593f05854440cbc16623bdf30abbbf6f5 0 1632791091000 6 connected 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 slave 0431cb8079fb3b9fb1df687ff4472d83f003eb38 0 1632791093000 2 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 slave 74fcaf33e74e0b537be4e539edbd075ba7462334 0 1632791093000 1 connected 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632791093000 6 connected 0-5000 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632791094225 2 connected 10001-16383
(3) 重新分片:借助 redis-cli --cluster reshard 命令对集群重新分片,使得各节点槽位均衡(分别从节点7000/7001/7002中迁移一些slot到节点7006中)。需要指定:
移动的槽位数:最终平均每个主节点有4096个slot,因此总共移动4096 slots
接收槽位的目标节点ID:节点7006的ID
移出槽位的源节点ID:节点7000/7001/7002的ID
1 2 3 4 5 6 7 8 9 10 11 12 13 # redis-cli --cluster reshard 172.16.5.8 7000 ./redis-cli --cluster reshard 172.16.5.8:7000 --cluster-from 9e904f9593f05854440cbc16623bdf30abbbf6f5,74fcaf33e74e0b537be4e539edbd075ba7462334,0431cb8079fb3b9fb1df687ff4472d83f003eb38 --cluster-to b4e28457008108d23ba30c0ae4b03034c7d6830f --cluster-slots 4096 172.16.5.8:7000> CLUSTER NODES 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632791537063 1 connected 6251-10000 b4e28457008108d23ba30c0ae4b03034c7d6830f 172.16.5.8:7006@17006 master - 0 1632791536041 7 connected 0-1249 5001-6250 10001-11596 c5290e4bd86416fc6cf6ddbbd98ef7acd0f4b5df 172.16.5.8:7007@17007 master - 0 1632791536000 0 connected f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,slave 9e904f9593f05854440cbc16623bdf30abbbf6f5 0 1632791536000 6 connected 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 slave 0431cb8079fb3b9fb1df687ff4472d83f003eb38 0 1632791538000 2 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 slave 74fcaf33e74e0b537be4e539edbd075ba7462334 0 1632791536000 1 connected 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632791539080 6 connected 1250-5000 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632791539000 2 connected 11597-16383
(4) 设置主从关系
1 2 3 4 5 6 7 8 9 10 11 ./redis-cli -h 172.16.5.8 -p 7007 cluster replicate b4e28457008108d23ba30c0ae4b03034c7d6830f 172.16.5.8:7000> CLUSTER NODES 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632791736742 1 connected 6251-10000 b4e28457008108d23ba30c0ae4b03034c7d6830f 172.16.5.8:7006@17006 master - 0 1632791736000 7 connected 0-1249 5001-6250 10001-11596 c5290e4bd86416fc6cf6ddbbd98ef7acd0f4b5df 172.16.5.8:7007@17007 slave b4e28457008108d23ba30c0ae4b03034c7d6830f 0 1632791737000 7 connected f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,slave 9e904f9593f05854440cbc16623bdf30abbbf6f5 0 1632791736000 6 connected 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 slave 0431cb8079fb3b9fb1df687ff4472d83f003eb38 0 1632791737749 2 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 slave 74fcaf33e74e0b537be4e539edbd075ba7462334 0 1632791736000 1 connected 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632791736000 6 connected 1250-5000 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632791738757 2 connected 11597-16383
删除节点 将新添加的两个节点7006和7007删除,需要将节点7006上分配的槽位迁移到其他节点。redis-cli --cluster reshard命令,将7006节点上的槽位全部转移到节点7000上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 ./redis-cli --cluster reshard 172.16.5.8 7006 root@ubuntu:/usr/local/redis/cluster/7000# ./redis-cli --cluster reshard 172.16.5.8 7006 > >> Performing Cluster Check (using node 172.16.5.8:7006) M: b4e28457008108d23ba30c0ae4b03034c7d6830f 172.16.5.8:7006 slots:[0-1249],[5001-6250],[10001-11596] (4096 slots) master 1 additional replica(s) M: 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001 slots:[6251-10000] (3750 slots) master 1 additional replica(s) S: c5290e4bd86416fc6cf6ddbbd98ef7acd0f4b5df 172.16.5.8:7007 slots: (0 slots) slave replicates b4e28457008108d23ba30c0ae4b03034c7d6830f S: f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000 slots: (0 slots) slave replicates 9e904f9593f05854440cbc16623bdf30abbbf6f5 S: 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005 slots: (0 slots) slave replicates 0431cb8079fb3b9fb1df687ff4472d83f003eb38 M: 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003 slots:[1250-5000] (3751 slots) master 1 additional replica(s) S: 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004 slots: (0 slots) slave replicates 74fcaf33e74e0b537be4e539edbd075ba7462334 M: 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002 slots:[11597-16383] (4787 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. > >> Check for open slots... > >> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 4096 What is the receiving node ID? 9e904f9593f05854440cbc16623bdf30abbbf6f5 #7003必须是master Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1: b4e28457008108d23ba30c0ae4b03034c7d6830f #7006 Source node #2: done 172.16.5.8:7000> CLUSTER NODES 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632792140149 1 connected 6251-10000 b4e28457008108d23ba30c0ae4b03034c7d6830f 172.16.5.8:7006@17006 master - 0 1632792139000 7 connected c5290e4bd86416fc6cf6ddbbd98ef7acd0f4b5df 172.16.5.8:7007@17007 slave 9e904f9593f05854440cbc16623bdf30abbbf6f5 0 1632792138000 8 connected f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,slave 9e904f9593f05854440cbc16623bdf30abbbf6f5 0 1632792138000 8 connected 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 slave 0431cb8079fb3b9fb1df687ff4472d83f003eb38 0 1632792139143 2 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 slave 74fcaf33e74e0b537be4e539edbd075ba7462334 0 1632792139000 1 connected 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632792138000 8 connected 0-6250 10001-11596 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632792141158 2 connected 11597-16383
(2) 删除节点: 利用redis-cli --cluster del-node命令依次删除从节点7006和主节点7007。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ./redis-cli --cluster del-node 172.16.5.8:7000 b4e28457008108d23ba30c0ae4b03034c7d6830f > >> Removing node b4e28457008108d23ba30c0ae4b03034c7d6830f from cluster 172.16.5.8:7000 > >> Sending CLUSTER FORGET messages to the cluster... > >> Sending CLUSTER RESET SOFT to the deleted node. ./redis-cli --cluster del-node 172.16.5.8:7000 c5290e4bd86416fc6cf6ddbbd98ef7acd0f4b5df > >> Removing node c5290e4bd86416fc6cf6ddbbd98ef7acd0f4b5df from cluster 172.16.5.8:7000 > >> Sending CLUSTER FORGET messages to the cluster... > >> Sending CLUSTER RESET SOFT to the deleted node. 172.16.5.8:7000> CLUSTER NODES 74fcaf33e74e0b537be4e539edbd075ba7462334 172.16.5.8:7001@17001 master - 0 1632792332000 1 connected 6251-10000 f039edd523b1b2fe79589edc693e7701454cf83f 172.16.5.8:7000@17000 myself,slave 9e904f9593f05854440cbc16623bdf30abbbf6f5 0 1632792335000 8 connected 560242d50f63ebb5f349791893ed2094cb2939bd 172.16.5.8:7005@17005 slave 0431cb8079fb3b9fb1df687ff4472d83f003eb38 0 1632792333765 2 connected 1a1e5eaa5269e1ed37b5b28877781086c4fe0591 172.16.5.8:7004@17004 slave 74fcaf33e74e0b537be4e539edbd075ba7462334 0 1632792334771 1 connected 9e904f9593f05854440cbc16623bdf30abbbf6f5 172.16.5.8:7003@17003 master - 0 1632792335778 8 connected 0-6250 10001-11596 0431cb8079fb3b9fb1df687ff4472d83f003eb38 172.16.5.8:7002@17002 master - 0 1632792333000 2 connected 11597-16383
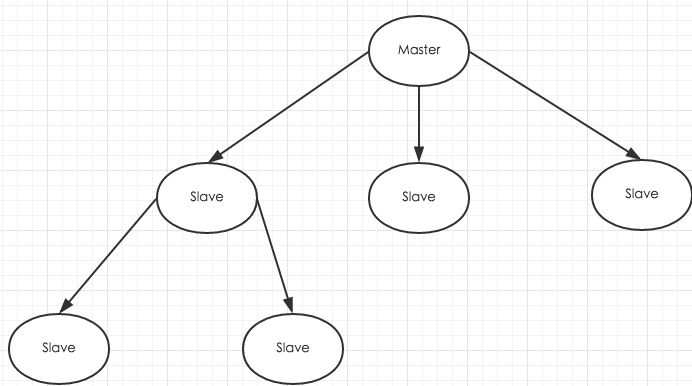
主从模式搭建 和MySQL需要主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生性能瓶颈,特别是在读压力上,为了分担压力,Redis支持主从复制。Redis的主从结构一主一从,一主多从或级联结构,复制类型可以根据是否是全量而分为全量同步和增量同步。
主从原理 全量同步 Redis全量复制一般发生在slave的初始阶段,这时slave需要将master上的数据都复制一份,具体步骤如下:
增量复制 增量复制实际上就是在slave初始化完成后开始正常工作时master发生写操作同步到slave的过程。增量复制的过程主要是master每执行一个写命令就会向slave发送相同的写命令,slave接受并执行写命令,从而保持主从一致。
主从同步的策略 主从同步刚连接的时候进行全量同步;全量同步结束后开始增量同步。如果有需要,slave在任何时候都可以发起全量同步,其主要策略就是无论如何首先会尝试进行增量同步,如果步成功,则会要求slave进行全量同步,之后再进行增量同步。
主从同步的特点 (1)、采用异步复制;
主从搭建 一主二从
1 2 3 4 5 6 mkdir /usr/local/redis/ms cd /usr/local/redis/ms mkdir run log data mkdir 800{0,1,2} cd data mkdir 800{0,1,2}
拷贝执行文件
1 2 3 cp -a /usr/local/redis/bin/* /usr/local/redis/ms/8000/ cp -a /opt/redis-6.2.5/redis.conf /usr/local/redis/ms/8000/ cd /usr/local/redis/ms/8000/
修改配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vi /usr/local/redis/ms/8000/redis.conf # 任意ip都可以连接 bind 0.0.0.0 # 端口 port 8000 # 关闭保护,允许非本地连接 protected-mode no # pid存储目录 pidfile /usr/local/redis/ms/run/redis_8000.pid # 日志存储目录 logfile /usr/local/redis/ms/log/redis_8000.log # 数据存储目录,目录要提前创建好 dir /usr/local/redis/ms/data/8000 # 持久化文件 dbfilename "dump-8000.rdb" # 持久化 appendonly yes # 守护进程 daemonize yes
将8000目录下的文件拷贝到8001~8003目录中,并修改redis.conf,替换配置文件中的8000, sed 's/8000/8001/g' ./8000/redis.conf > ./8001/redis.conf./8001/redis.conf和./8002/redis.conf两个从节点中指定主节点
1 2 # 主信息 slaveof 172.16.5.8 8000
启动主从
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 cd /usr/local/redis/ms/8000 ./redis-server redis.conf cd /usr/local/redis/ms/8001 ./redis-server redis.conf cd /usr/local/redis/ms/8002 ./redis-server redis.conf ps -ef|grep redis ./redis-cli -h 172.16.5.8 -p 8000 172.16.5.8:8000> INFO ... # Replication role:master # 8000为master connected_slaves:2 slave0:ip=172.16.5.8,port=8001,state=online,offset=98,lag=0 #8001为slave slave1:ip=172.16.5.8,port=8002,state=online,offset=98,lag=0 #8002为slave master_failover_state:no-failover master_replid:31dd7decaaa663e3b3b51863fccf6b2a9af14762 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:98 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:98 # CPU used_cpu_sys:0.029451 used_cpu_user:0.029451 used_cpu_sys_children:0.000759 used_cpu_user_children:0.000736 used_cpu_sys_main_thread:0.029438 used_cpu_user_main_thread:0.029438 # Modules # Errorstats # Cluster cluster_enabled:0 # Keyspace
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 # --raw 支持中文显示 ./redis-cli -h 172.16.5.8 -p 8000 --raw 172.16.5.8:8000> set name 'test' OK 172.16.5.8:8000> get name test 172.16.5.8:8000> exit ./redis-cli -h 172.16.5.8 -p 8001 --raw 172.16.5.8:8001> get name test 172.16.5.8:8001> set name 'pass' # 在从节点只能读取不能写入 READONLY You can't write against a read only replica.
开机自启服务
1 2 mkdir /usr/local/redis/ms/script cd /usr/local/redis/ms/script
启动脚本
1 2 3 4 # !/bin/sh /usr/local/redis/ms/8000/redis-server /usr/local/redis/ms/8000/redis.conf /usr/local/redis/ms/8001/redis-server /usr/local/redis/ms/8000/redis.conf /usr/local/redis/ms/8002/redis-server /usr/local/redis/ms/8000/redis.conf
停止脚本
1 2 3 4 # !/bin/sh /usr/local/redis/ms/8000/redis-cli -p 8000 shutdown /usr/local/redis/ms/8001/redis-cli -p 8001 shutdown /usr/local/redis/ms/8002/redis-cli -p 8002 shutdown
重启脚本
1 2 3 # !/bin/sh systemctl stop redis-ms systemctl start redis-ms
修改权限
编写开机服务
1 2 cd /usr/lib/systemd/system/ vi redis-ms.service
1 2 3 4 5 6 7 8 9 10 [Unit] Description=redis-ms After=network.target remote-fs.target nss-lookup.target [Service] Type=forking ExecStart=/usr/local/redis-ms/script/start.sh ExecStop=/usr/local/redis-ms/script/stop.sh ExecReload=/usr/local/redis-ms/script/restart.sh [Install] WantedBy=multi-user.target
服务命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 修改权限 chmod 777 redis-ms.service # 进程服务重加载 systemctl daemon-reload # 开机启动主从 systemctl enable redis-ms.service # 启动主从 systemctl start redis-ms.service # 关闭主从 systemctl stop redis-ms.service # 重启主从 systemctl restart redis-ms.service
Redis哨兵 Redis哨兵机制 在主从复制实现之后,如果想对master进行监控,Redis提供了一种哨兵机制,哨兵的含义就是监控Redis系统的运行状态,并做相应的响应。
哨兵的功能 其主要的功能有以下两点:
哨兵的任务 哨兵主要用于管理多个Redis服务器,主要有以下三个任务:
哨兵的工作原理 哨兵是一个分布式系统,你可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议来接收关于Master是否下线的信息,并使用投票协议来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master。
监控 sentinel会每秒一次的频率与之前创建了命令连接的实例发送PING,包括主服务器、从服务器和sentinel实例,以此来判断当前实例的状态。down-after-milliseconds时间内PING连接无效,则将该实例视为主观下线。之后该sentinel会向其他监控同一主服务器的sentinel实例询问是否也将该服务器视为主观下线状态,当超过某quorum后将其视为客观下线状态。
故障迁移 首先是从主服务器的从服务器中选出一个从服务器作为新的主服务器。选点的依据依次是:网络连接正常->5秒内回复过INFO命令->10*down-after-milliseconds内与主连接过的->从服务器优先级->复制偏移量->运行id较小的。选出之后通过slaveif no ont将该从服务器升为新主服务器。
缺点 (1)、主从服务器的数据要经常进行主从复制,这样会造成性能下降;
哨兵模式搭建 1 2 3 mkdir /usr/local/redis/sentinel cd /usr/local/redis/sentinel mkdir run log data
拷贝执行文件
1 2 cp -a /usr/local/redis/bin/* /usr/local/redis/sentinel cp -a /opt/redis-6.2.5/sentinel.conf /usr/local/redis/sentinel
修改配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vi /usr/local/redis/sentinel/sentinel.conf # pid存储目录 pidfile /usr/local/redis/sentinel/run/sentinel.pid # 日志存储目录 logfile /usr/local/redis/sentinel/log/sentinel.log # 工作路径,注意路径不要和主重复 dir /usr/local/redis/sentinel/data # 哨兵监控的master,主从配置一样,这里只用输入redis主节点的ip/port和法定人数。 sentinel monitor mymaster 172.16.5.8 8000 1 # master或slave多长时间(默认30秒)不能使用后标记为s_down状态。 sentinel down-after-milliseconds mymaster 5000 # 若sentinel在该配置值内未能完成failover操作(即故障时master/slave自动切换),则认为本次failover失败。 sentinel failover-timeout mymaster 18000 # 指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步,有几个slave就设置几个 sentinel parallel-syncs mymaster 2
启动哨兵
1 2 3 4 ./redis-server sentinel.conf --sentinel # 运行另一个终端 ./redis-cli -p 26379
通过哨兵查看集群状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 127.0.0.1:26379> sentinel master mymaster 1) "name" 2) "mymaster" 3) "ip" 4) "172.16.5.8" 5) "port" 6) "8000" 7) "runid" 8) "ddbf6c16f07ae0917c3e79fb708f2f28e2d0e086" 9) "flags" 10) "master" ... 127.0.0.1:26379> sentinel slaves mymaster 1) 1) "name" 2) "172.16.5.8:8001" 3) "ip" 4) "172.16.5.8" 5) "port" 6) "8001" ... 2) 1) "name" 2) "172.16.5.8:8002" 3) "ip" 4) "172.16.5.8" 5) "port" 6) "8002" ...
模拟主down掉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 ./redis-cli -h 172.16.5.8 -p 8000 172.16.5.8:8000> SHUTDOWN 127.0.0.1:26379> sentinel master mymaster 1) "name" 2) "mymaster" 3) "ip" 4) "172.16.5.8" 5) "port" 6) "8002" # 切换到8002 7) "runid" 8) "51c4cd8d5902ff9a451f8064c13b772080209d4f" 9) "flags" 10) "master" ... 127.0.0.1:26379> sentinel slaves mymaster 1) 1) "name" 2) "172.16.5.8:8000" 3) "ip" 4) "172.16.5.8" 5) "port" 6) "8000" # 8000变成从节点 7) "runid" 8) "" 9) "flags" 10) "slave" ... 2) 1) "name" 2) "172.16.5.8:8001" 3) "ip" 4) "172.16.5.8" 5) "port" 6) "8001" 7) "runid" 8) "60d9cefe3fdf4a942514bbf5fbf90e93fb2ff2d6" 9) "flags" 10) "slave" ...
即使8000恢复了仍然是8002的slave,也不会变成master。
编程实战
Redis Cluster | go-redis (uptrace.dev)
主从(非集群) 1.如果把3个sentinel实例全部 kill掉,则go-redis会记录一条日志,而对redis的读写操作仍然正常。
2.如果只kill掉1个sentinel,则剩余两个sentinel还能正常监测redis主从切换。
3.当3个sentinel都正常运行的情况下,动态增减从节点对客户端没有影响。例如增加一个从节点127.0.0.1:8003再把原从节点127.0.0.1:8002 shutdown,客户端没有影响。进而把主节点127.0.0.1:8000 shutdown,迫使主从切换,结果证明客户端能够切换到新的主节点127.0.0.1:8003上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package mainimport ( "context" "fmt" "github.com/go-redis/redis/v8" "time" ) func main () rdb := redis.NewFailoverClient(&redis.FailoverOptions{ MasterName: "mymaster" , SentinelAddrs: []string { "172.16.5.8:26379" , }, DB: 0 , Password: "" , DialTimeout: 200 * time.Microsecond, ReadTimeout: 200 * time.Microsecond, WriteTimeout: 200 * time.Microsecond, }) if s,err := rdb.Ping(context.Background()).Result();err != nil { panic (err) } else { fmt.Println(s) } for { reply,err := rdb.Incr(context.Background(),"pvcount" ).Result() fmt.Printf("reply=%v err=%v\n" , reply, err) time.Sleep(1 * time.Second) } }
集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport ( "context" "fmt" "github.com/go-redis/redis/v8" "time" ) func main () rdb := redis.NewClusterClient(&redis.ClusterOptions{ Addrs: []string { "172.16.5.8:7001" , "172.16.5.8:7002" , "172.16.5.8:7003" , }, Password: "" , DialTimeout: 200 * time.Microsecond, ReadTimeout: 200 * time.Microsecond, WriteTimeout: 200 * time.Microsecond, }) if s,err := rdb.Ping(context.Background()).Result();err != nil { panic (err) } else { fmt.Println(s) } if err := rdb.Set(context.Background(), "name" ,"哈哈" , time.Second*60 ).Err();err != nil { panic (err) } if val,err := rdb.Get(context.Background(), "name" ).Result();err != nil { panic (err) } else { fmt.Println(val) } }
参考 参考:
https://mp.weixin.qq.com/s/KT8kGgzn6TQwBGCUkMw_4g https://www.cnblogs.com/coolops/p/12809893.html