Prometheus + Grafana监控
本文包括 Prometheus 概述、部署、配置、监控、告警、之前我做监控用的都是 zabbix,zabbix 也算是一个全面型的监控系统,但是他不太适合容器监控,他对容器监控集成欠缺很多,他比较偏向于非容器监控。
Prometheus 算是一个全能型选手,原生支持容器监控,当然监控传统应用也不是吃干饭的,所以就是容器和非容器他都支持,所有的监控系统都具备这个流程,数据采集→数据处理→数据存储→数据展示→告警,本文就是针对 Prometheus 展开的,所以先看看 Prometheus 概述
Prometheus 概述
Prometheus 是什么
中文名普罗米修斯,最初在 SoundCloud 上构建的监控系统,自 2012 年成为社区开源项目,用户非常活跃的开发人员和用户社区,2016 年加入 CNCF,成为继 kubernetes 之后的第二个托管项目,官方网站
Prometheus 特点
- 多维数据模型:由度量名称和键值对标识的时间序列数据
- PromSQL: — 种灵活的查询语言,可以利用多维数据完成复杂的查询
- 不依赖分布式存储,单个服务器节点可直接工作
- 基于 HTTP 的 pull 方式釆集时间序列数据
- 推送时间序列数据通过 PushGateway 组件支持
- 通过服务发现或静态配罝发现目标
- 多种图形模式及仪表盘支持 (grafana)
Prometheus 组成与架构
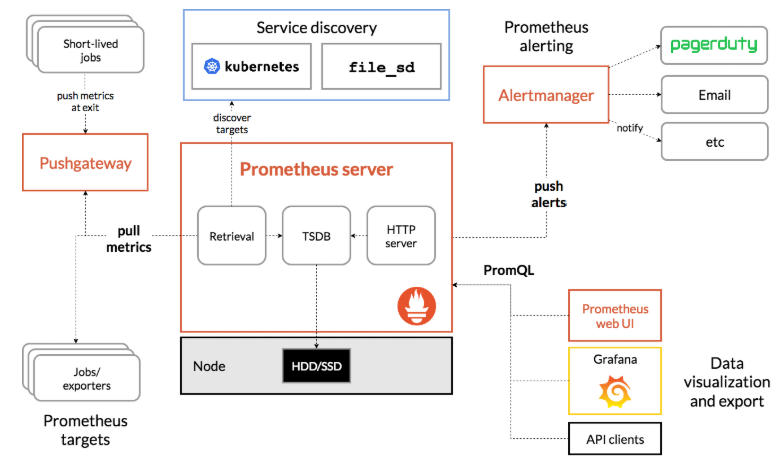
| 名称 | 说明 |
|---|---|
| Prometheus Server | 收集指标和存储时间序列数据,并提供查询接口 |
| Push Gateway | 短期存储指标数据,主要用于临时性任务 |
| Exporters | 采集已有的三方服务监控指标并暴露 metrics |
| Alertmanager | 告警 |
| Web UI | 简单的 WEB 控制台 |
集成了数据的采集,处理,存储,展示,告警一系列流程都已经具备了
数据模型
Prometheus 将所有数据存储为时间序列,具有相同度量名称以及标签属于同个指标,也就是说 Prometheus 从数据源拿到数据之后都会存到内置的 TSDB 中,这里存储的就是时间序列数据,它存储的数据会有一个度量名称,譬如你现在监控一个 nginx,首先你要给他起个名字,这个名称也就是度量名,还会有 N 个标签,你可以理解名称为表名,标签为字段,所以,每个时间序列都由度量标准名称和一组键值对 (也称为标签) 唯一标识。
时间序列的格式是这样的,
1 | <metrice name> {<label name>=<label value>,...} |
metrice name 指的就是度量标准名称,label name 也就是标签名,这个标签可以有多个,栗子
1 | nginx_http_access{method="GET",uri="/index.html"} |
这个度量名称为 nginx_http_access,后面是两个标签,和他们各对应的值,当然你还可以继续指定标签,你指定的标签越多查询的维度就越多。
指标类型
看表格吧
| 类型名称 | 说明 |
|---|---|
| Counter | 递增计数器,适合收集接口请求次数 |
| Guage | 可以任意变化的数值,适用 CPU 使用率 |
| Histogram | 对一段时间内数据进行采集,并对有所数值求和于统计数量 |
| Summary | 与 Histogram 类型类似 |
作业和实例
实例指的就是你可以抓取的目标,这个会在 Prometheus 配置文件中提现,作业是具有相同目标的实例集合称为作业,你可以理解为是一个组,一会写配置文件的时候会详细解析,下面开始安装 Prometheus。
Prometheus 部署
先通过二进制来部署 Prometheus 吧,下载地址,我们要下载服务端,也就是这个包
我在服务器上直接下载了,下载完后解压移动到别的目录。
1 | [root@rj-bai ~]# wget https://github.com/prometheus/prometheus/releases/download/v2.10.0/prometheus-2.10.0.linux-amd64.tar.gz |
先配置一下监控本机吧,它默认的配置文件是 prometheus.yml,已经配置好了,也就是这一段,
1 | - job_name: 'prometheus' |
targets 就是一个作业,也就是被监控端,监控本机的 9090 端口,启动选项也有很多,了解一下,主要是关注两点,分别如下。
1 | --storage.tsdb.path="data/" ##存储数据的目录,默认/data |
这里提一下存储的问题,TSDB 不太适合长期去存储数据,数据量大了支持并不是很好,官方声明也是不会对这一块存储进行改善,给你的建议是使用外部存储,譬如使用 InfluxDB,这里暂时就不改他的默认存储了,把他进入系统服务吧,写一个 systemd 的配置文件,直接启动了
1 | [root@rj-bai /usr/local/prometheus]# cat > /usr/lib/systemd/system/prometheus.service <<OEF |
这样就启动了撒,去访问 9090 端口就可以看到页面了,这个页面能看到的东西很多,自己点点看吧,能看到这个页面就表示莫得问题。
目前使用二进制部署主要是因为方便改配置文件,下面开始看配置文件。
全局配置文件介绍
prometheus 已经安装起来了,下面看一下配置文件与核心功能,很多功能都是通过配置文件去实现的,比较多,所以先熟悉一下他的配置文件。
全局配置文件
也就是 prometheus.yml,官方说明地址,大概分为这几块,我把注释去掉了,全局配置选项
1 | global: |
指定告警规则
1 | rule_files: |
配置被监控端
1 | scrape_configs: |
配置告警方式
1 | alerting: |
指定远程存储
1 | remote_write: |
这就是一个整体的配置文件,现在再看默认的配置文件就能看懂某一段是干啥的了,现在开始配置 scrape_configs
scrape_configs
这块就是来配置我们要监控的东西,在这一块中配置的东西又有很多了,看一下官方的,一堆,我还是去掉注释分段贴出来吧。
1 | job_name: <job_name> ##指定job名字 |
它默认暴露监控数据的接口就是 ip:9090/metrics,你可以去指定这个名称,访问一下这里看看,

在 ip:9090/targets 能看到当前监控的主机,现在只有本机一个,标签显示也在这里。

在看下一段,这里定义的是要如何去访问采集目标
1 | [ scheme: <scheme> | default = http ] ## 默认使用http方式去访问 |
下一段,服务发现配置,贴了几个,不是完整的
1 | consul_sd_configs: ##通过consul去发现 |
静态配置被监控端
1 | static_configs: |
刚刚监控本机的就是静态配置去监控的,也是就这一段,
1 | scrape_configs: |
最后标签配置
1 | relabel_configs: |
下面看一下 relabel_configs
relabel_configs
就是用来重新打标记的,对于 prometheus 数据模型最关键点就是一个指标名称和一组标签来组成一个多维度的数据模型,你想完成一个复杂的查询就需要你有很多维度,relabel_configs 就是对标签进行处理的,他能帮你在数据采集之前对任何目标的标签进行修改,重打标签的意义就是如果标签有重复的可以帮你重命名,看一哈现在的,上面铁锅

现在 instance 是他默认给我加的标签,想改的话就需要 relabel_configs 去帮你重打标签,他也可以删除标签,如果某个标签用不到了也可以删掉,再就是过滤标签,再看一下 relabel_configs 的配置有哪些,也就是这一段
1 | relabel_configs: |
这东西到底怎么用,做个演示,根据两台服务器聚合查看 CPU 使用率,说白了就是同时去查看这两台服务器的 CPU 利用率,用这个标签就可以实现了。
添加标签
去 WEB 界面看一下当前被监控端 CPU 使用率,用 sql 去查,也就是这个值。
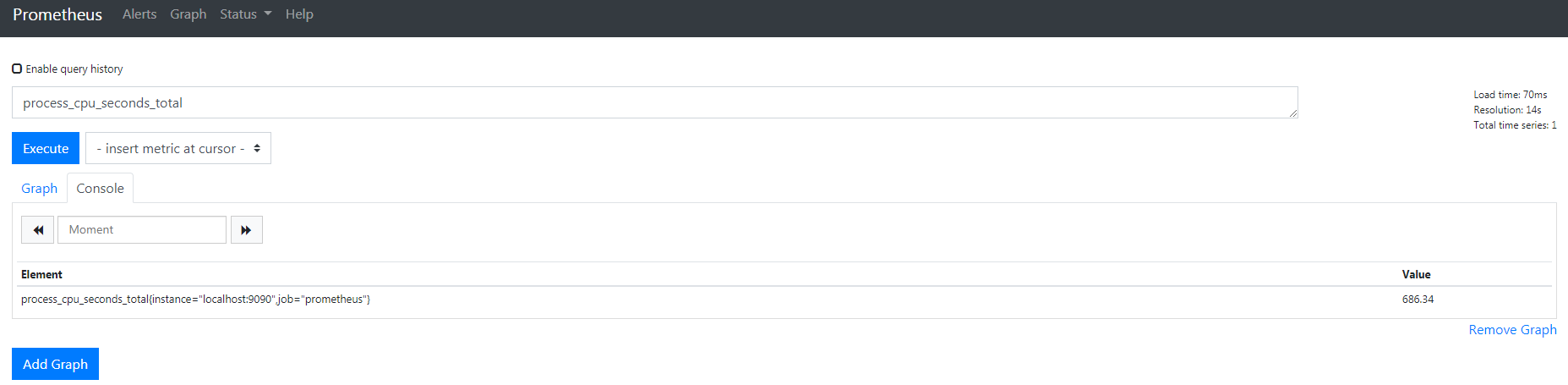
可以看到一个度量名称和两个默认附加的标签,我现在想统计两台服务器的 CPU 使用率,就需要加一个标签了,说白了就是添加一个维度去获取这两台服务器 CPU 使用率,接下来去改配置文件吧,给他加个标签,如下,
1 | static_configs: |
热更新一下,
1 | [root@rj-bai /usr/local/prometheus]# ps aux | grep prometheus.yml | grep -v grep | awk {'print $2'} | xargs kill -hup |
看一下有没有生效,刷新一下页面就能看到了,
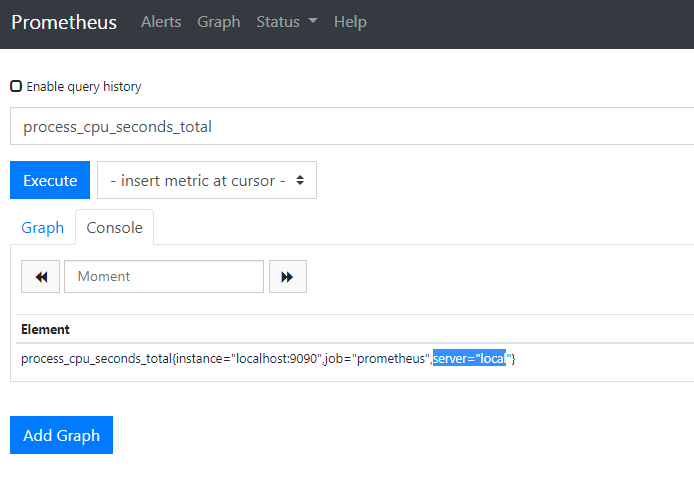
然后可以根据这个标签去查了,语法是这样的,内置函数,
1 | sum(process_cpu_seconds_total{server="local"}) |
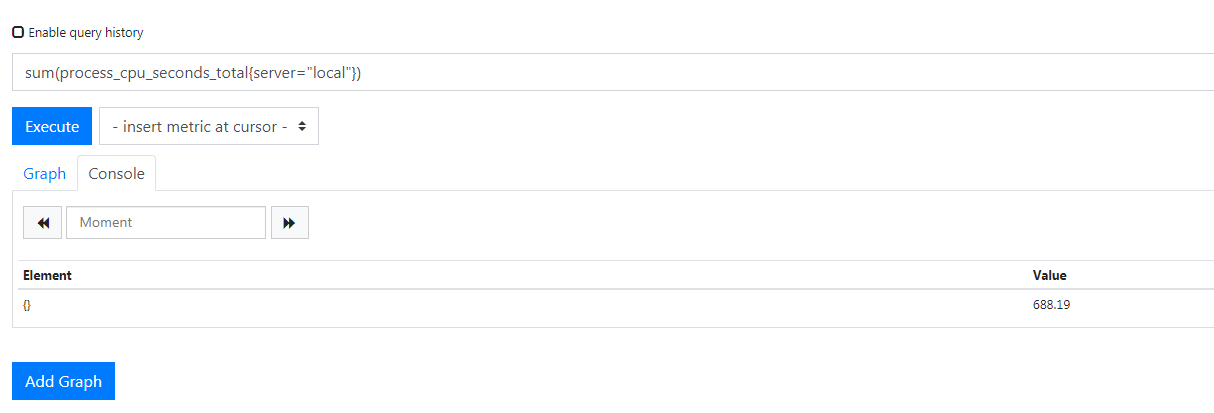
所以就算你有 N 个被监控的服务器打上这个标签之后在这里就可以看到总数了,添加标签很简单,下面看一下重命名标签,就是将现有的标签进行重命名。
标签重命名
就是将一个已有的标签重命名一个新的标签,实际操作一下,之前的标签去掉了,现在要把 job_name 改个名字,也就是这一块的配置,
1 | - job_name: 'prometheus' |
目前 job_name 为 prometheus,当前这个虚拟机是跑在 IP 地址为 21 的物理机上,所以现在把他的 job_name 改成 server21,
1 | scrape_configs: |
重启一下,刷新页面就可以看到了,
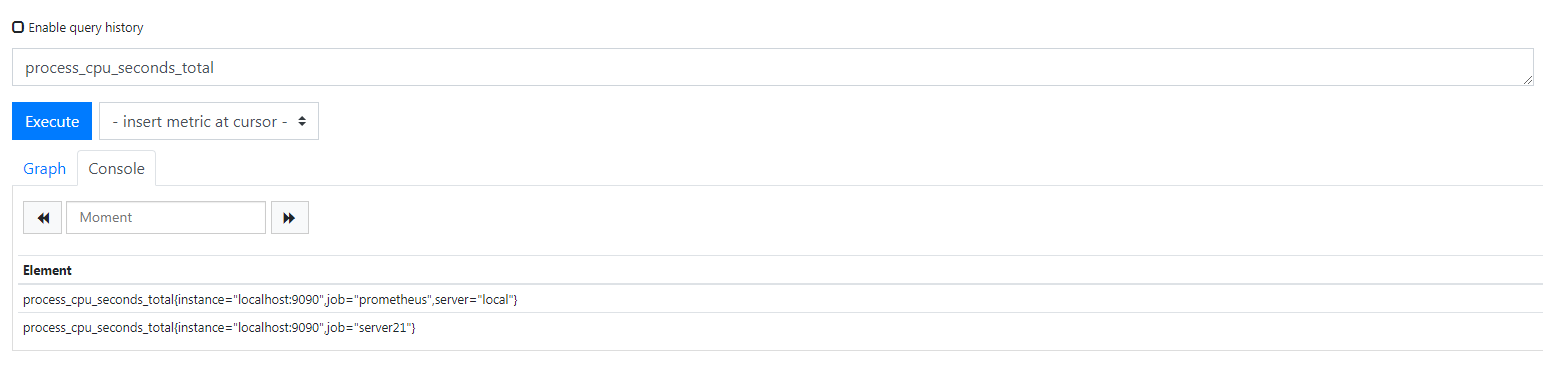
我现在要将 job 这个标签标记为 local,也就是将 job="server21 改为 local="server21,下面开始用 relabel 进行重命名,改完之后的配置是这样的,
1 | scrape_configs: |
这样就可以了撒,重新加载一下,看页面,
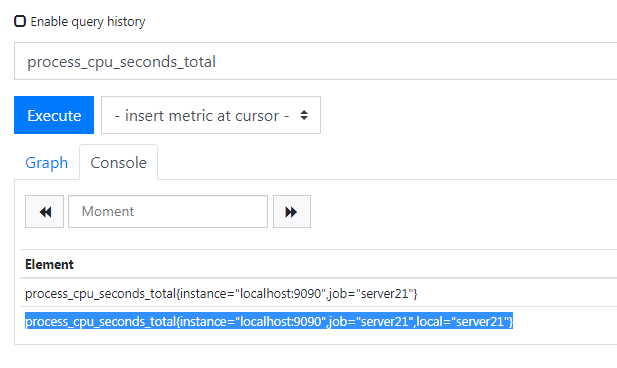
新的数据已经有了,之前的标签还会保留,因为没有配置删除他,这样就可以了,现在就可以聚合了,
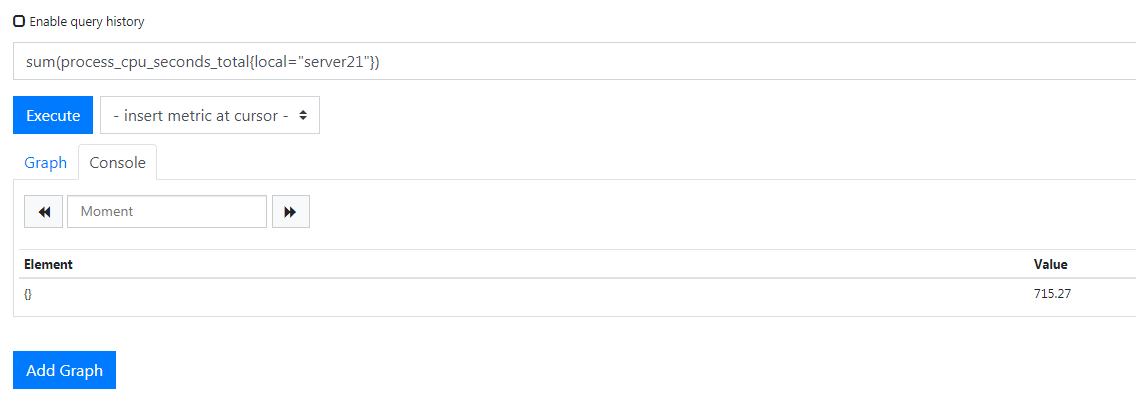
这样他就会将所有实例使用率相加求和。
action 重新打标签动作
如表所示,上面就是用了一个默认的。
| 值 | 描述 |
|---|---|
| replace | 默认,通过正则匹配 source_label 的值,使用 replacement 来引用表达式匹配的分组 |
| keep | 删除 regex 于链接不匹配的目标 source_labels |
| drop | 删除 regex 与连接匹配的目标 source_labels |
| labeldrop | 匹配 Regex 所有标签名称 |
| labelkeep | 匹配 regex 所有标签名称 |
| hashmod | 设置 target_label 为 modulus 连接的哈希值 source_lanels |
| labelmap | 匹配 regex 所有标签名称,复制匹配标签的值分组,replacement 分组引用 (${1},${2}) 替代 |
比如说我现在不想采集本机的数据了,就可以用上面的标签进行操作了,加点东西就行了,
1 | scrape_configs: |
删除标签为 job 的节点,目前只有一个节点,所以这个跑了之后就看不到数据了,如果真的要用这个给不需要监控的节点打一个标签,然后在这里匹配就行了,所以现在重新载入的话就没数据了,
最后看一下删除标签。
删除标签
刚刚我新打了一个标签,也就是 local 标签,所以之前的 job 标签可以不要了,下面直接给他删了吧,
1 | scrape_configs: |
重载一下就看到 job 的标签了。
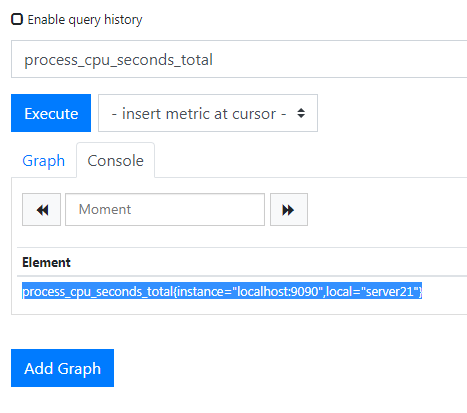
这样就可以了撒,下面看看基于文件的服务发现功能
基于文件的服务发现
下面会涉及到基于文件的服务发现,还有就是基于 kubernetes 的服务发现,这个到监控 k8s 集群的时候再说吧,先看基于文件的吧,现在还没准备别的服务器,还是发现本身吧,先把配置文件改成这样,重载之后就看不到本机了。
1 | [root@rj-bai /usr/local/prometheus]# cat prometheus.yml |
然后就可以去改配置文件了,通过服务发现将自身加入进去,
1 | [root@rj-bai /usr/local/prometheus]# cat prometheus.yml |
重载服务,然后去写服务发现的 YAML 文件吧,
1 | [root@rj-bai /usr/local/prometheus/files_sd_configs]# cat configs.yml |
这样就可以了,文件保存五秒后就能看到发现的主机了,查数据也没问题
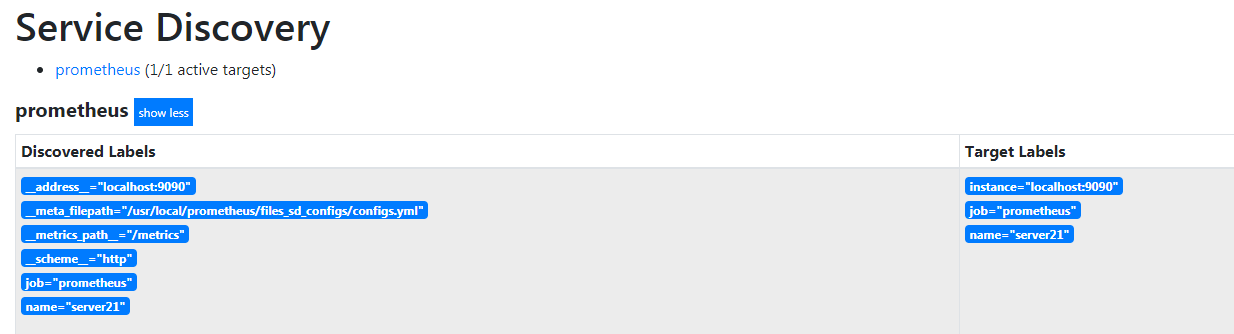

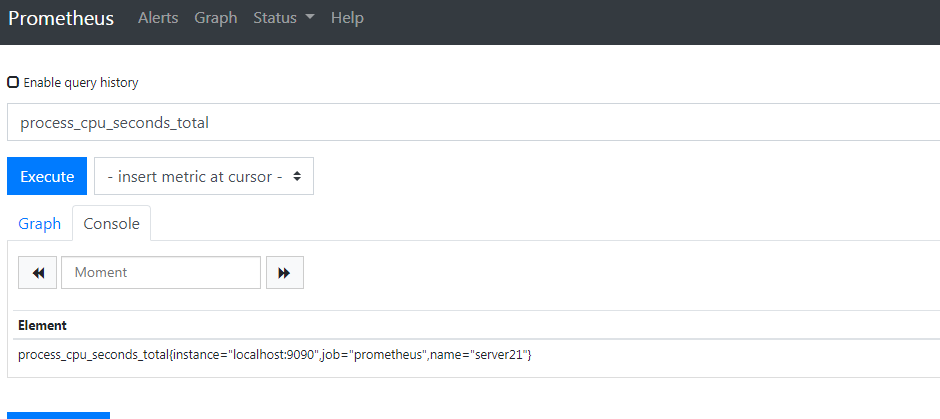
就是这种原理,下面开始监控 linux 和一些服务吧
监控例子
监控 linux 服务器
在被监控端需要装一个名为 node_exporter 的导出器,他会帮你收集系统指标和一些软件运行的指标,把指标暴露出去,这样 prometheus 就可以去采集了,具体 node_exporter 能采集哪些东西,看官方的 github吧,还是蛮多的,现在随便找个服务器下载一下 node_exporter 运行起来就行了。
1 | [root@kubeadm-node ~]# wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz |
在启动之前看一下他的启动参数,
1 | [root@kubeadm-node /usr/local/node_exporter]# ./node_exporter --help |
可以看到一堆,她就是一个收集器,配置你要收集或不收集哪些信息,看 default 就能看出来撒,加到系统服务中吧,用 systemctl 去管理。
1 | [root@kubeadm-node /usr/local/node_exporter]# cat > /usr/lib/systemd/system/node_exporter.service <<OEF |
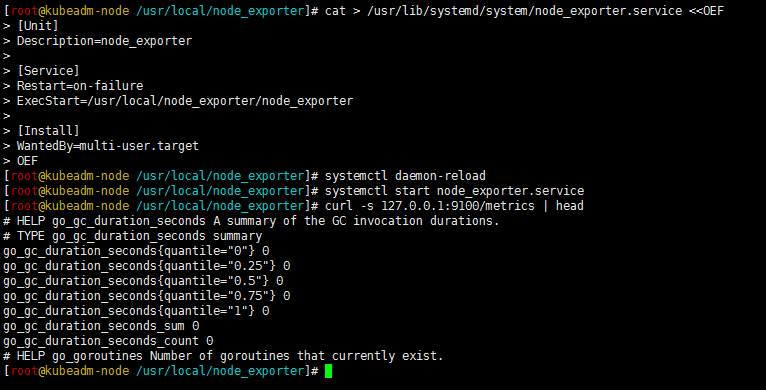
正常启动了,现在要配置 prometheus 来监控这个主机了,之前配置过动态发现了,现在再加一个,把服务端和被监控端分开,所以新加了这个。
1 | [root@rj-bai /usr/local/prometheus]# cat prometheus.yml |
直接去看页面吧,应该已经添加进去了,顺便查一下数据
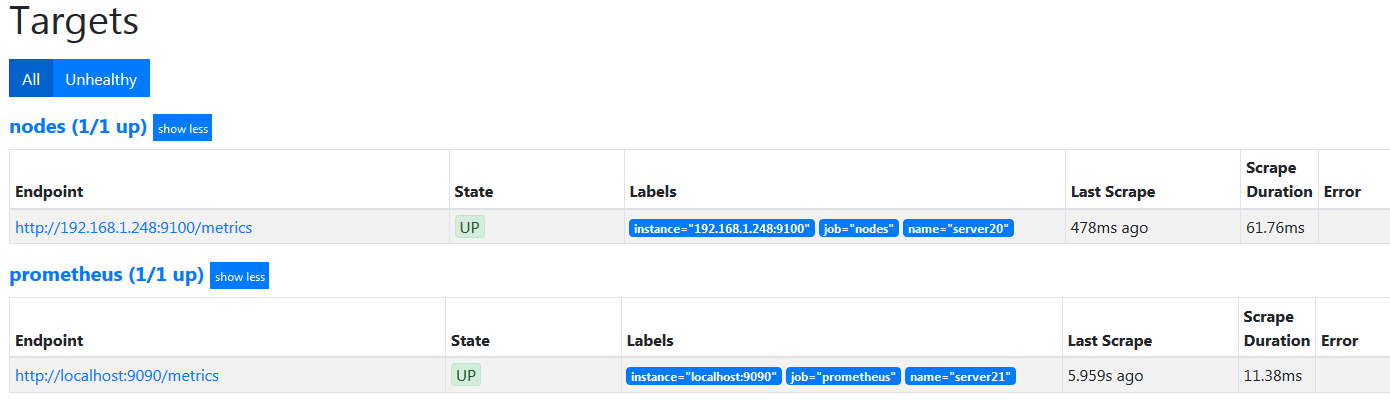
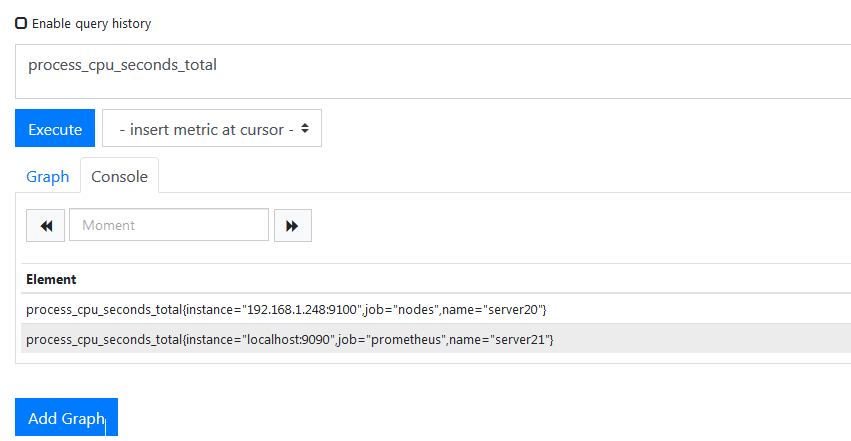
这样就可以了,莫得问题,下面用 PromSQL 获取 CPU& 内存硬盘使用率
使用 PromSQL
想查数据就需要写 PromSQL 去查询了,
查询 CPU 使用率
比如果我想查看刚刚加进来的 nodes CPU 利用率,以 node 开头的 sql 都是 node_expores 采集的指标,度量很多,看 CPU 使用率看着一个指标就够了,
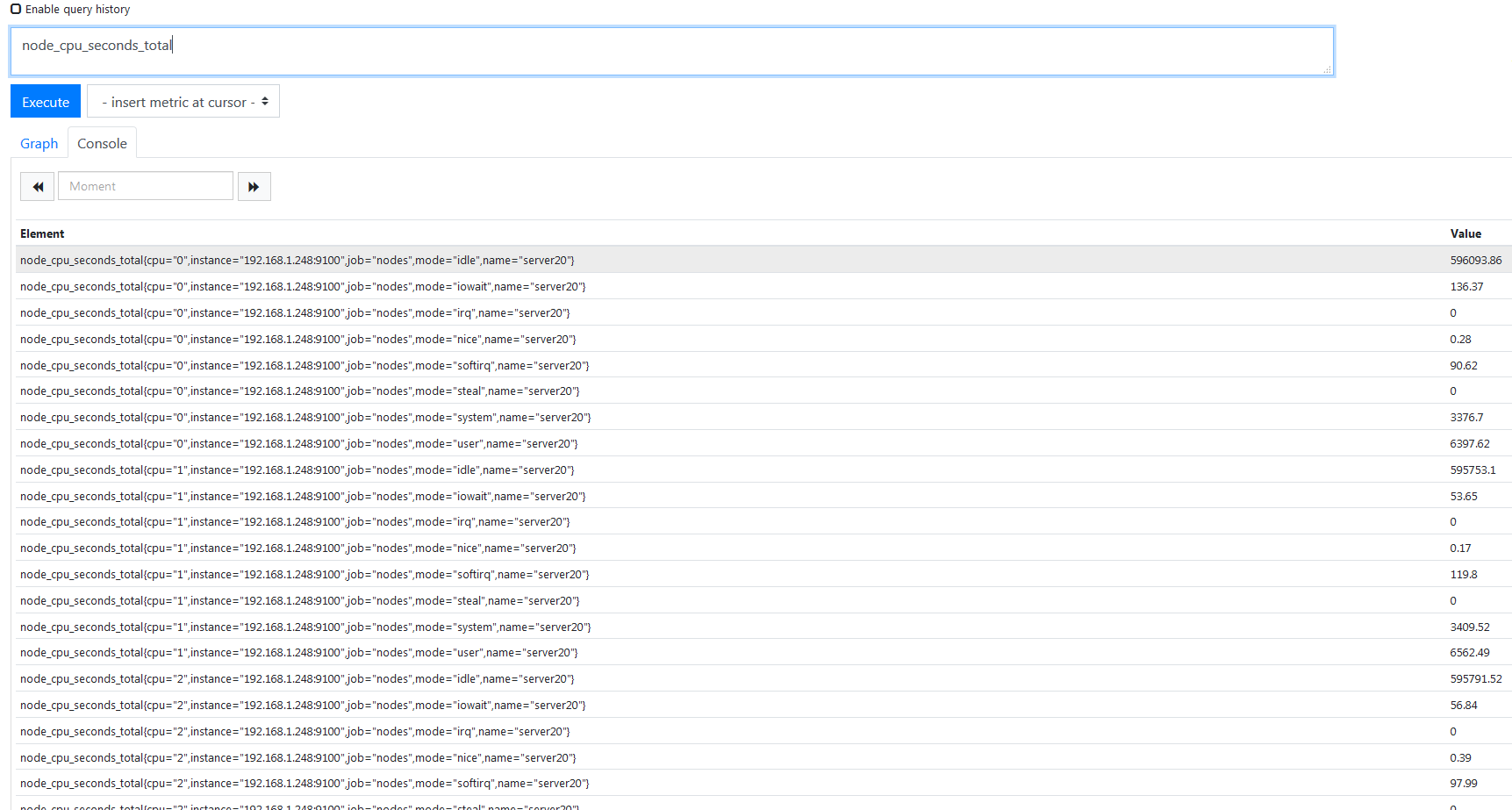
总 CPU 使用情况,会列出你处理器多少核,每个核的使用情况,这个 CPU 是干什么使用的,用户态还是内核态还是操作 IO 等待的时间,还有优先级调度使用的 CPU,他会通过一个名为 mode 的标签去区分这些,一般不会这么去统计,现在统计一下刚刚加进去的那个 nodes 五分钟之内 CPU 平均使用率是多少,还是得写 PromSQL,大概是这样,
1 | 100 - irate(node_cpu_seconds_total{mode="idle"}[5m])*100 |
node_cpu_seconds_total{mode="idle"}[5m] 这一段是统计出了服务器最近 5 分钟 CPU 的空闲率,执行之后是这种效果,
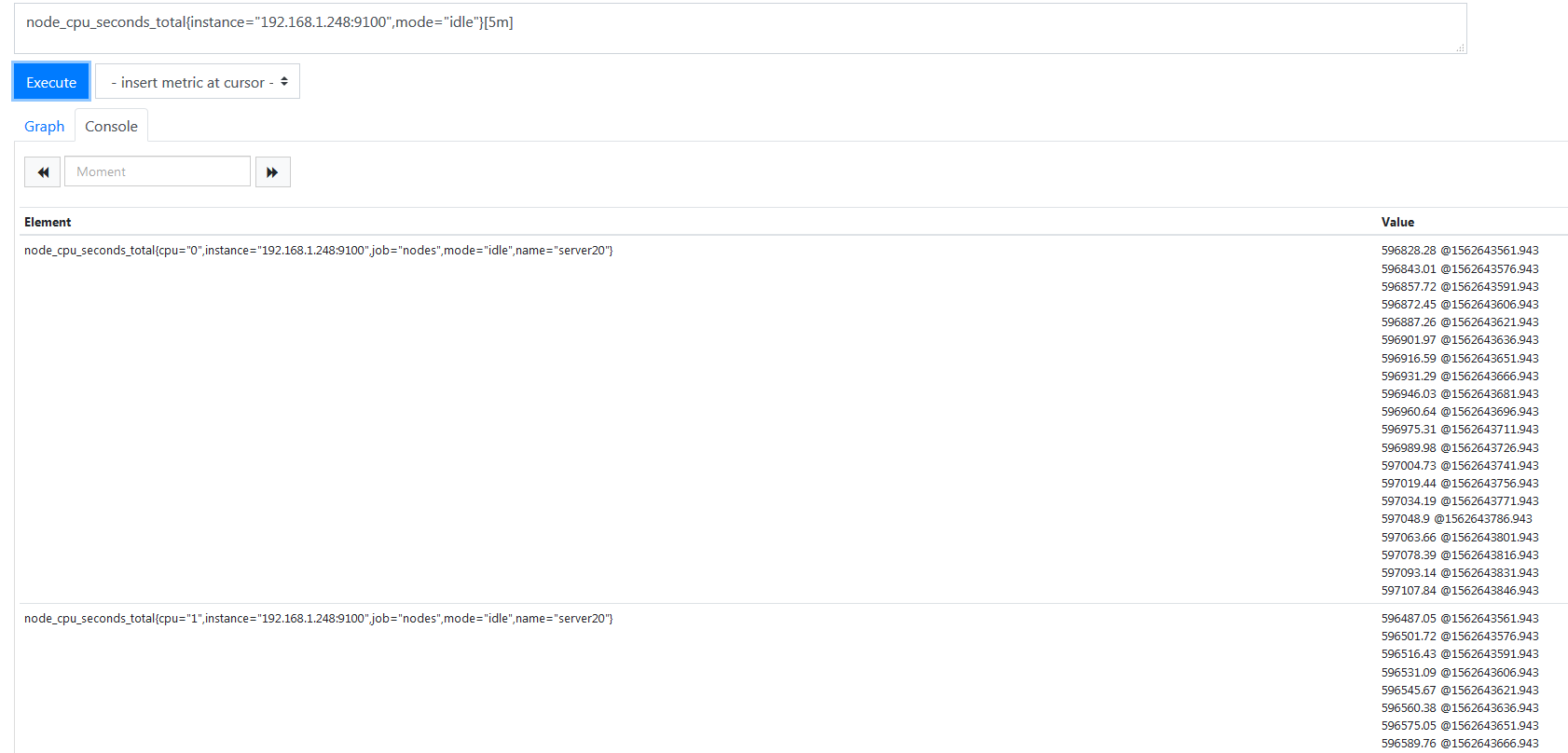
这是五分钟之内所有值,然后使用了 irate 函数来统计它的平均值,转化成了百分比,乘了一百,所以执行结果如下。
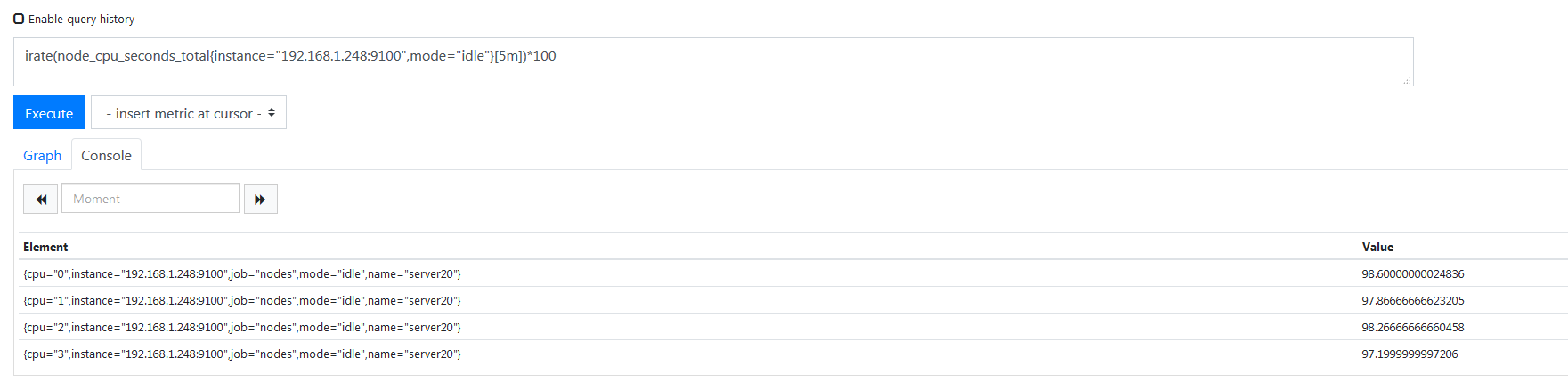
这就是所有 CPU 的空闲率了,我要取的是所有 CPU 的使用率,所以又一百减去了空闲率的值就是使用率了,所以上面第一条 sql 执行发回的结果如下。
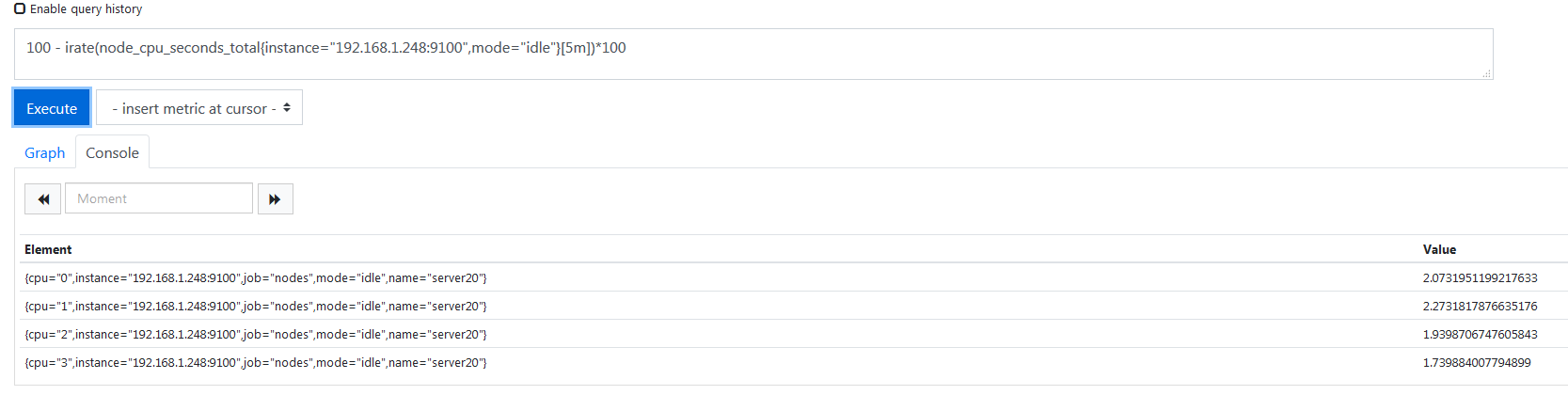
这就是五分钟之内总的 CPU 的平均使用率了,我的那个节点就是四核 CPU,每个都被列出来了,真鸡儿麻烦,再看一下内存使用率,和上面其实一样,值都有了,求出他的百分比就行了,
查询内存使用率
linux 内核有一个内存缓存机制,所以 buff/cache 的占用不算是已被使用的物理内存,所以计算方式就是将这三个值加到一起就是剩余内存了,

sql 的话这样写,直接查一下,
1 | node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes |
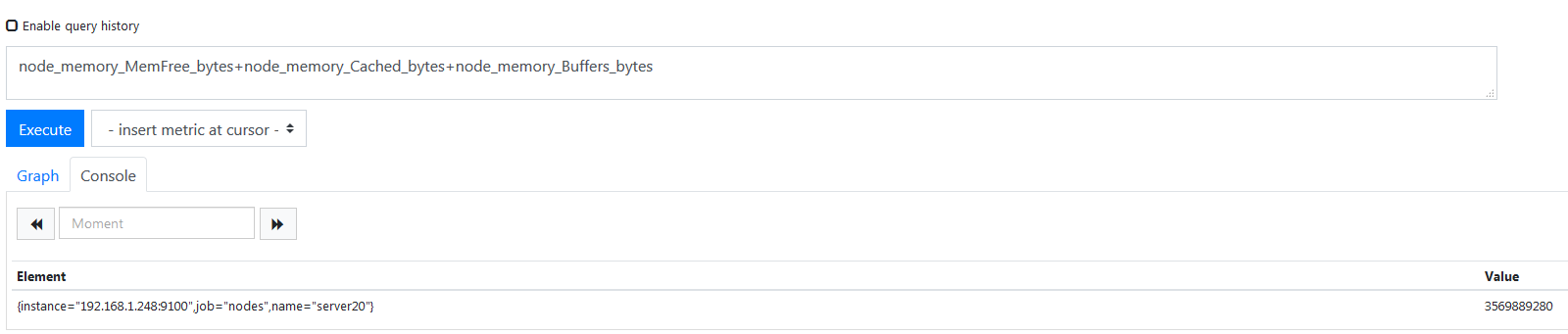
这就是总共剩余的内存,单位是 bite,现在我要计算使用内存百分比,和上面看 CPU 使用率的方法一致,sql 如下
1 | 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes *100 |
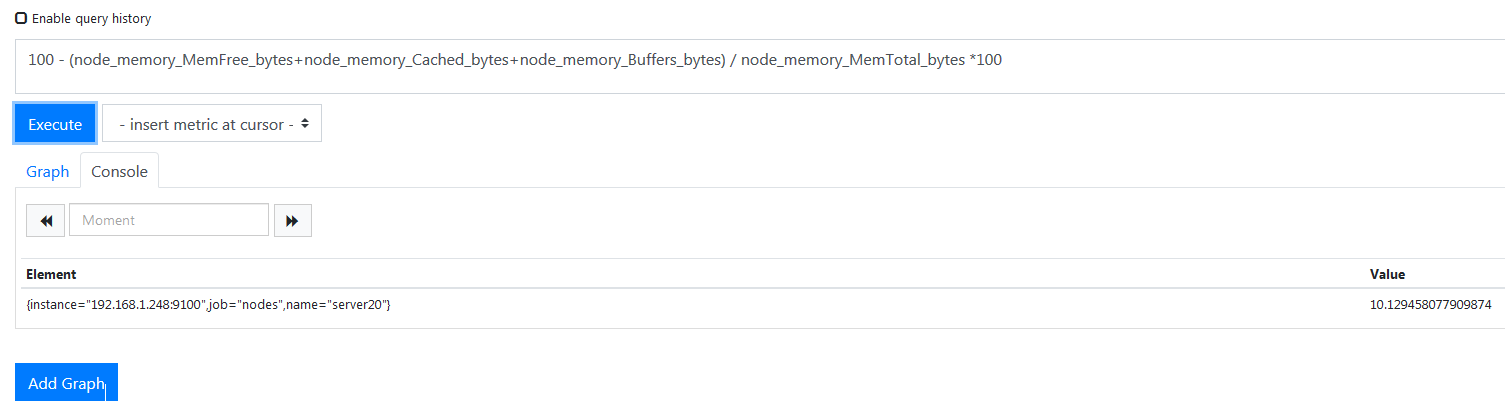
下面看看硬盘使用率
查询硬盘使用率
你的磁盘和挂载点可能不止一个,先看一下目前收集到的信息,
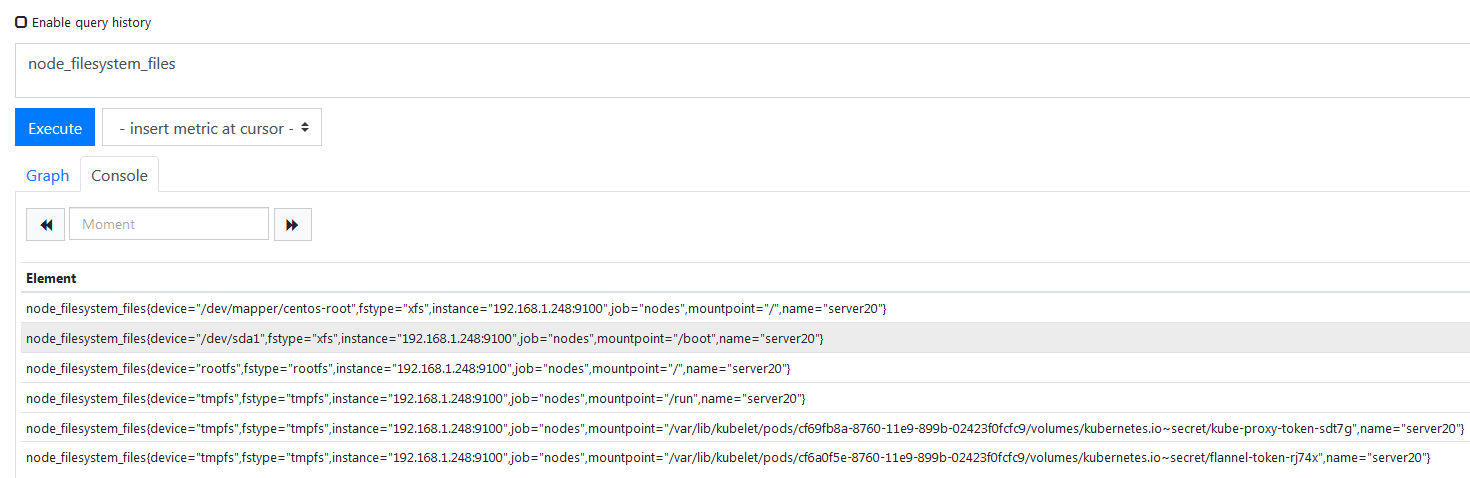
所以就要指定分区进行计算了,所以匹配这里写了一个正则去匹配你挂载的磁盘,如下
1 | 100- (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs"} *100) |
node_filesystem_size_bytes 查的是 / 总大小,node_filesystem_free_bytes 查的是剩余大小,只匹配 ext4&xfs 类型的,像是什么 tmpfs&shm 类型的都不匹配,还是算出了剩余的百分比,所以执行后的结果是这样,

计算方式大概就是这样,现在还没涉及到图形展示这一块,下面看一下获取系统服务运行状态。
查询系统服务运行状态
就是监控系统服务运行状态,说白了就是监控以 systemctl 启动的服务,现在监控一下这个,node_exports 就支持对这种服务进行监控,目前还没有启用这个功能,现在启动一下撒,直接去改 node_exports 的启动文件,加两条参数即可。
1 | [root@kubeadm-node ~]# cat /usr/lib/systemd/system/node_exporter.service |
第二段就是制定我要监控哪些系统服务,我写了 docker&sshd,重启后可以去查询了,
1 | [root@kubeadm-node ~]# systemctl daemon-reload |
我查一下当前 docker&sshd 的运行状态是什么,可以直接这样写了,
1 | node_systemd_unit_state{exported_name=~"(docker|sshd).service"} |
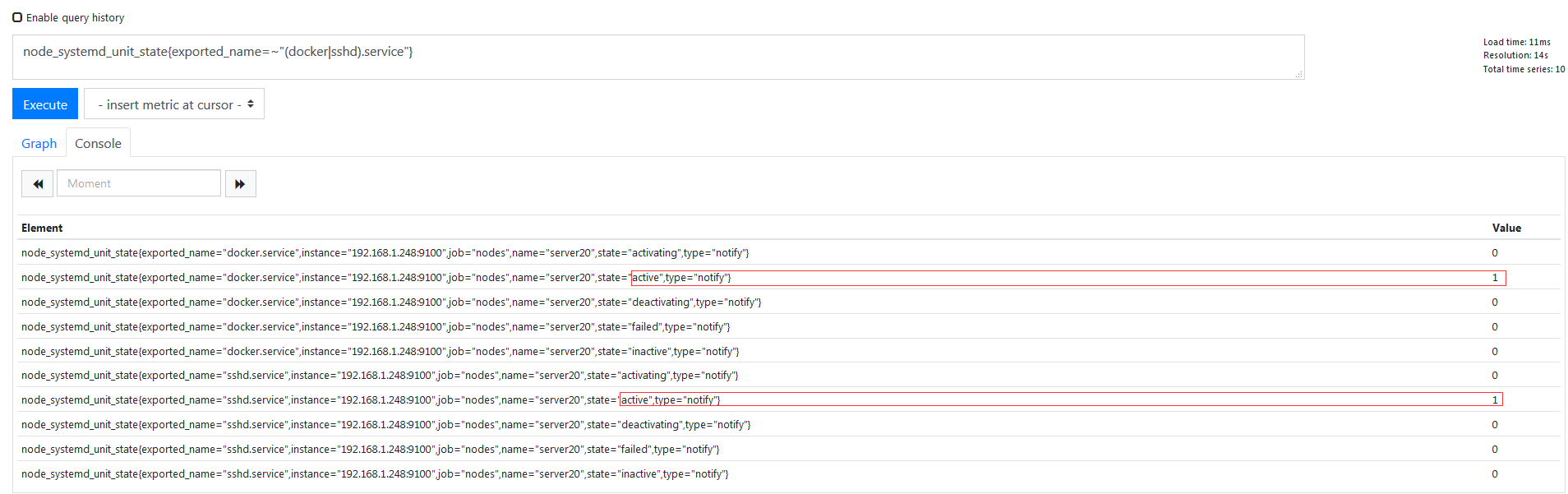
目前 state=active 的值为 0,说明正常运行,所以之后写告警规则的时候就去判断这个值是不是 1,如果不是就要进行某些操作了,下面装一下 grafana 吧
部署 grafana
grafana 就是一个图形展示系统,他主要是对度量指标进行分析可视化,他本身不会存储任何数据,他只会展示数据库里面的数据,支持很多类型的数据库,官网,刚好我装有 docker,其实目前在操作的这两台服务是一个 k8s 集群,用 kubeadm 启动的,所以我直接用 docker 启动了,还是写个 deployment,算了直接用 docker 命令启吧,
1 | [root@kubeadm-node ~]# docker run \ |
这样就行了,直接访问 3000 端口就好了,用户名密码默认 admin/admin,初次登陆会让你修改密码,就可以看到主页了,然后直接添加数据源,把 prometheus 加进去,保存就行了,
然后直接导入一个仪表盘进来吧,ID 是 9276,大概是这种效果,
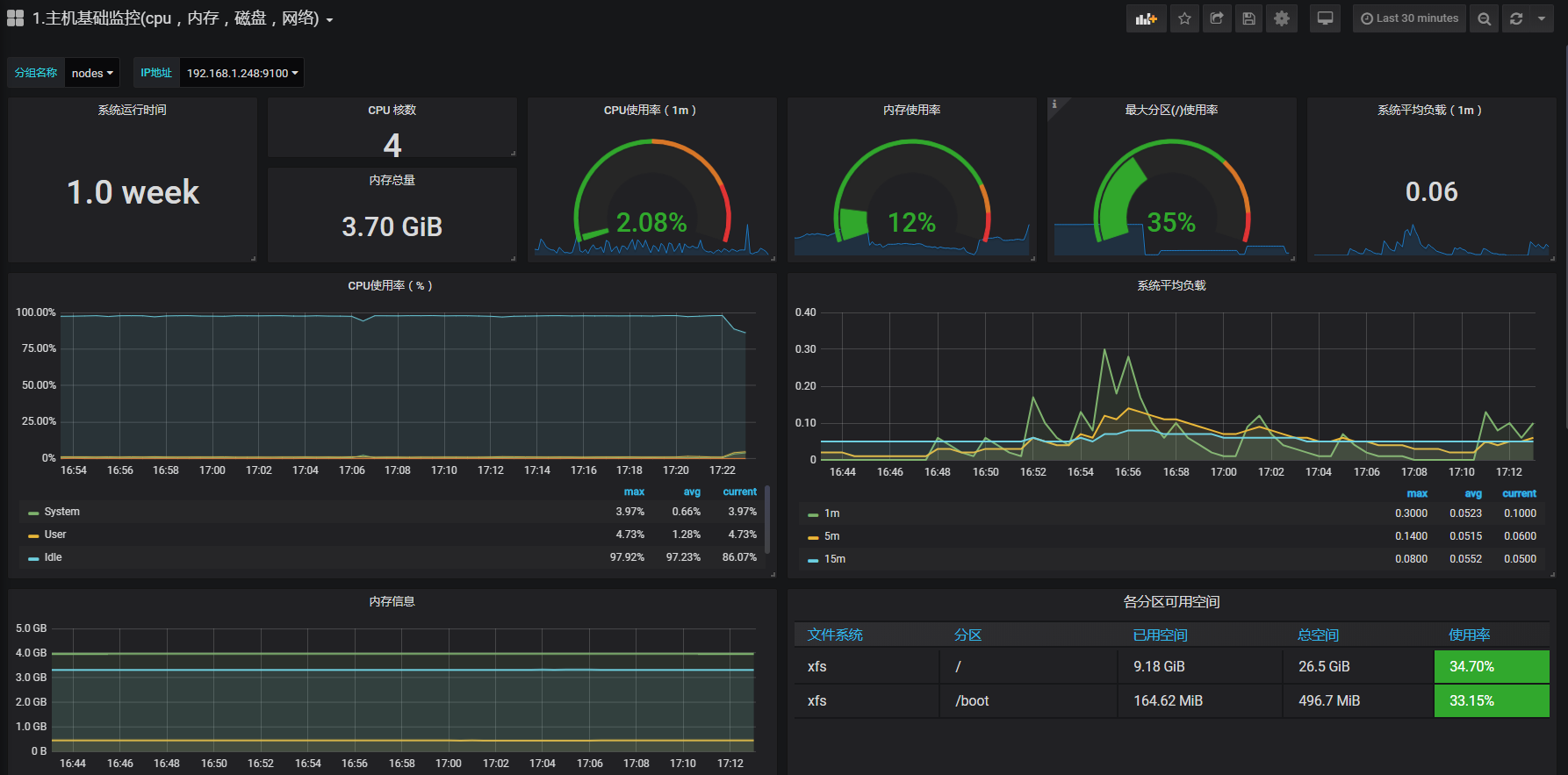
然后网络带宽那里没数据,我看了一下他的 sql,只需要将 $nic 改为你的网卡名就有数据了,所以现在监控 linux 服务器是没问题了,下面试试监控 docker。
监控 docker
想要监控 docker 需要用到名为 cadvisor 的工具,是谷歌开源的,它用于收集正在运行的容器资源使用和性能信息,github 地址,你需要在要监控的服务器上部署 cadvisor,直接用 docker 去启动就完了,命令如下
1 | docker run \ |
容器启动后也是会暴露一个指标接口,默认是 8080/metrics,这里就不访问了,下一步就是加入到普罗米修斯中进行监控了,去改他的配置文件,静态配置一个吧,
1 | - job_name: 'docker' |
加完直接重载,页面直接导入一个图表吧,ID 是 193,效果是这样的,
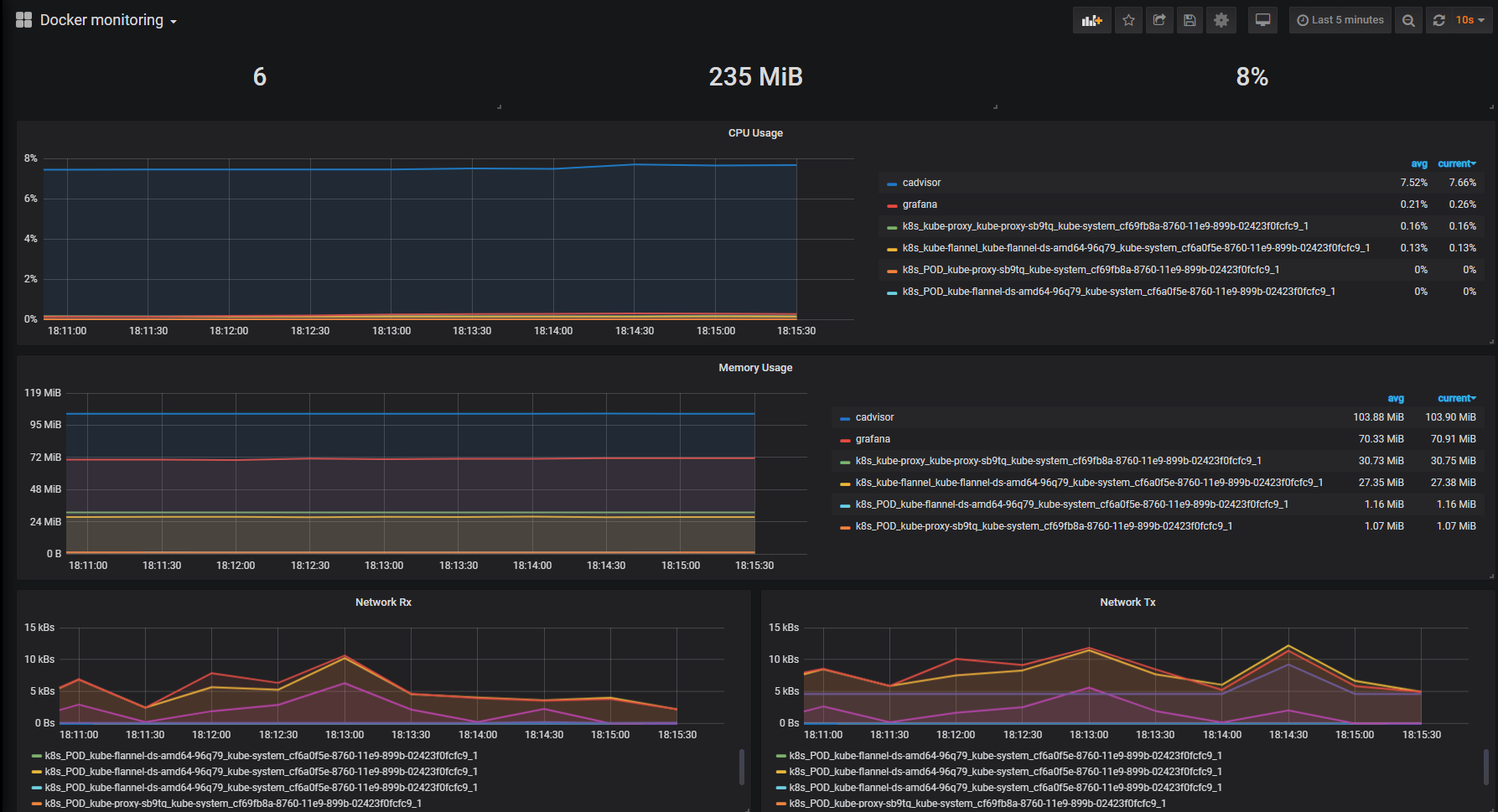
主要就是监控容器的 CPU 内存网络流量的,都可看到,目前我 248 就运行了六个容器,就是这样,下面在看看监控 mysql
监控 mysql
监控 mysql 就会用到 mysql_exporter,这个也能在官网下到,也就是这里,这个东西需要你安装到运行 mysql 的实例上,本地的 mysql 比较多,我随便找了一个扔了上去,先去 mysql 创建一个用户吧,这个程序需要连接明月三千里才能获取到指标。
1 | mysql> CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'exporter'; |
用户创建好了去解压包吧,
1 | [root@mysql ~]# tar zxf mysqld_exporter-0.11.0.linux-amd64.tar.gz -C /usr/local/ && cd /usr/local/ |
需要写一个文件,mysqld_exporter 直接读这个文件就可以连接 mysql 了,
1 | [root@mysql mysqld_exporter]# cat .my.cnd |
文件有了,在启动的时候指定一下读取这个文件,直接启动
1 | [root@mysql mysqld_exporter]# ./mysqld_exporter --config.my-cnf=.my.cnf |

现在把这个加到普罗米修斯中,
1 | - job_name: 'mysql' |
然后导入一个仪表盘,ID 为 7362,看页面,
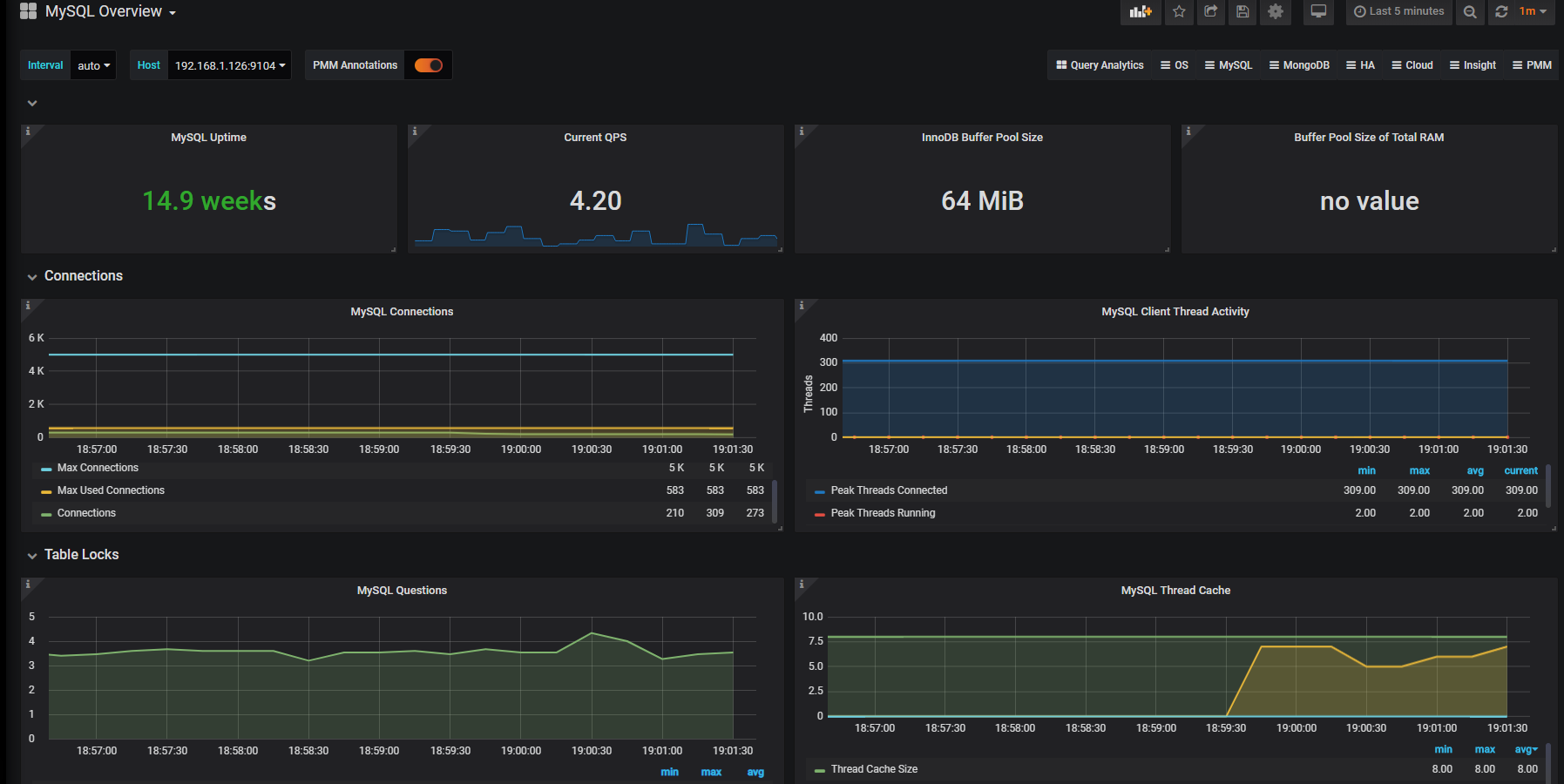
还是有些空值,而且官方也说了 5.6 版本有些不支持,我看了一下 Buffer Pool Size of Total RAM 的 sql,是这样写的,
1 | (mysql_global_variables_innodb_buffer_pool_size{instance="$host"} * 100) / on (instance) node_memory_MemTotal_bytes{instance="$host"} |
现在应该能看的差不多了,他去查了 mysql 节点的总内存,但是我明月三千里节点并没有装 node_exports,所以就没数据了,总之支持采集的数据和仪表盘模板很多,自行琢磨吧,上面只是最简单的几个例子,下面来看看告警这一块的东西。
alertmanager
普罗米修斯本身是不支持告警的,告警是由 alertmanager 这个组件完成的,普罗米修斯将告警收集起来会推送给 alertmanager,alertmanager 接收到告警后决定怎么去处理这些告警,应该发给谁,下面先部署一下 alertmanager 吧,我直接下载了,在普罗米修斯服务器上,
部署 alertmanager
alertmanager 没必要和普罗米修斯放在一个服务器上,他们之间能通讯就可以了,我目前资源紧张就扔到一起了,直接 wget 了,
1 | [root@rj-bai ~]# wget https://github.com/prometheus/alertmanager/releases/download/v0.18.0/alertmanager-0.18.0.linux-amd64.tar.gz |
让他先下着,聊一下普罗米修斯和 alertmanager 是怎么通讯的,首先你需要在 prometheus 中定义你的监控规则,说白了就是写一个触发器,某个值超过了我设置的阈值我就要告警了,触发告警之后 prometheus 会推送当前的告警规则到 alertmanager,alertmanager 收到了会进行一系列的流程处理,然后发送到接收人手里,他的处理规则也是很复杂的,后面会说,现在也下载完了,解压
1 | [root@rj-bai ~]# tar zxf alertmanager-0.18.0.linux-amd64.tar.gz |
有两个二进制文件,分别是启动程序和一个工具,还有一个主配置文件,先来了解一下他的主配置文件,
1 | global: |
全局配置,设置解析超时时间,
1 | route: |
这里是配置告警的,配置告警怎么发送,怎么来分配,
1 | receivers: |
这里是配置告警的接收者,我要发送给谁,
1 | inhibit_rules: |
这里用于配置告警收敛的,主要就是减少发送告警,来发送一些关键的,所以先把这段注释了吧,暂时用不到,之后会用到,所以基于这个配置文件改改,暂时先发送 email 吧,所以改完的配置文件如下,
1 | [root@rj-bai /usr/local/alertmanager]# cat alertmanager.yml |
保存后检查一下这个文件有没有问题,命令如下,
1 | [root@rj-bai /usr/local/alertmanager]# ./amtool check-config alertmanager.yml |
然后去启动吧,还是加到系统服务中吧,
1 | [root@rj-bai /usr/local/alertmanager]# cat > /usr/lib/systemd/system/alertmanager.service <<OEF |
现在 alertmanager 是装完了,需要和 prometheus 融合一下,需要配置两部分,分别如下,
1 | alerting: |
配置这两项就够了,保存之后创建 rules 目录,接下来就可以配置告警规则了。
配置告警规则并邮件通知
我直接在官方复制过来了一个例子顺便改了改,如下,
1 | [root@rj-bai /usr/local/prometheus/rules]# cat example.yml |
每个实例都会有一个 up 的指标,上面的标签名 job 都能看到,用 sql 去查一下,
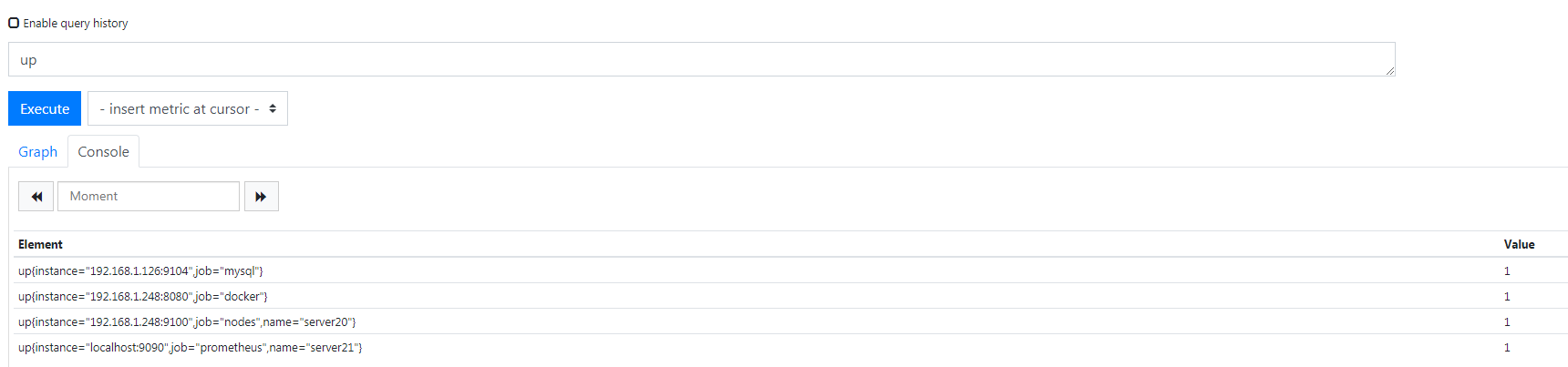
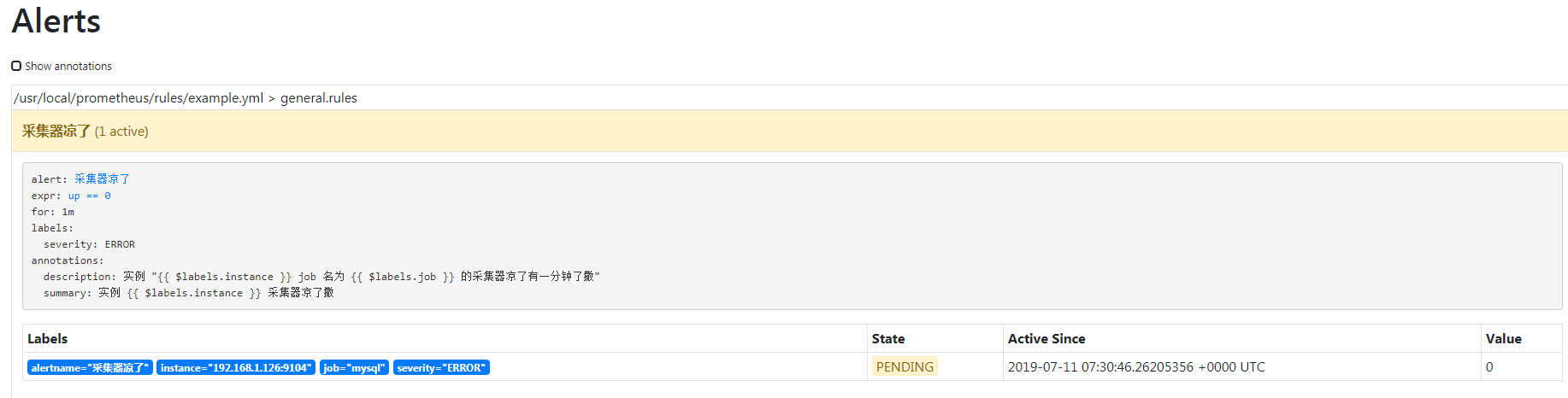
采集器在开启状态下返回值就是 1,如果采集器出现问题没启动或是什么别的异常都会返回 0,0 就是代表异常了,所以说白了就是那条规则就是监控所有实例的 up 指标,如果指标值为 0 且持续时间超过一分钟我就要告警了,保存吧,直接重启 prometheus 吧,重启之后可以在 web 控制台看到你配置的规则了,

既然配置完了,验证一下吧,随便关掉一个采集器,等邮件就行了,我把明月三千里的关掉了,然后发现有一条告警处于 PENDING 状态,他已经准备去通知 alertmanager 了,
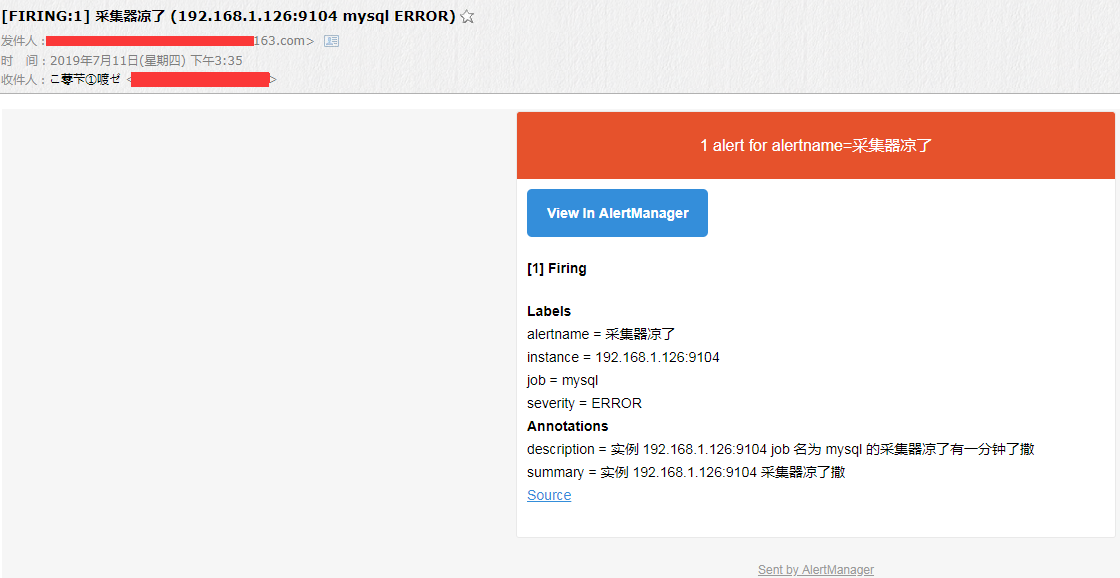
一分钟之后我收到邮件了,长这样,
如果问题没解决他每分钟都会给你发一封邮件,刚刚配置了,发送邮件的等待时间一会会细说一下,我再停一个,我再把 docker 停了,看看他发出的邮件是什么样的,
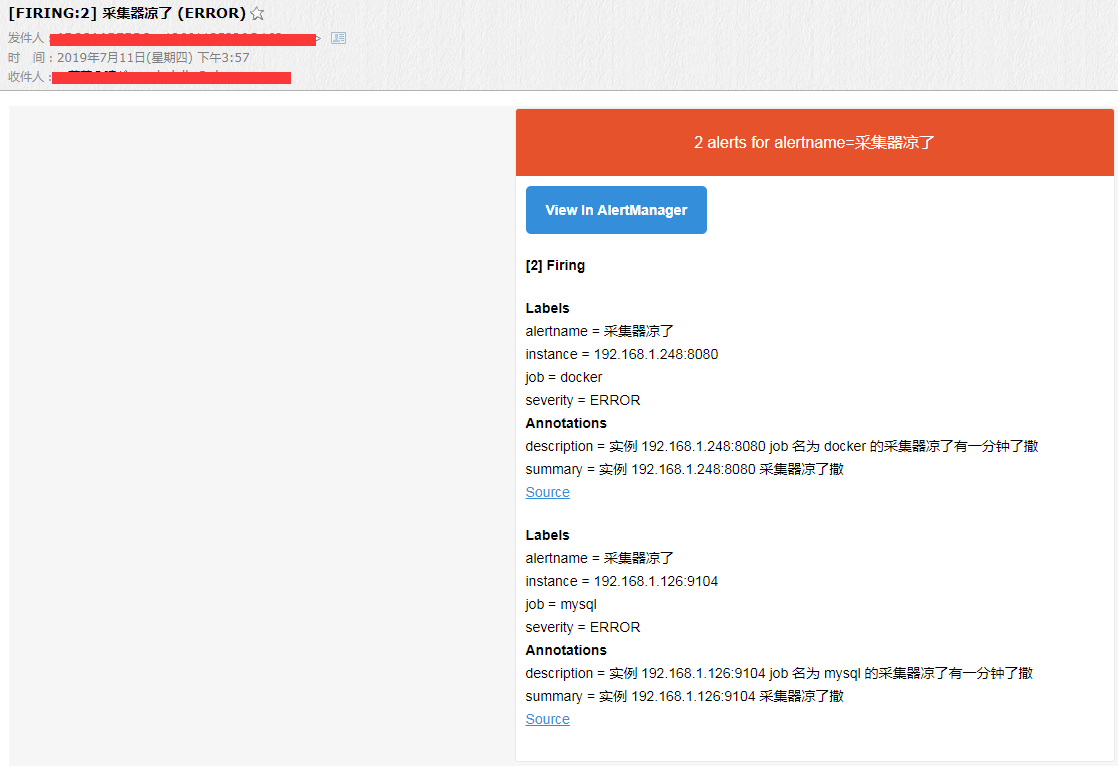
这里两条告警被合并到一个邮件里发出来了,这就是做了分组,如果你有同类告警的,也就是根据 alertname 去区分的,都会给你合并,mysql&docker 被合并到一起了,再看一下他还是支持哪些方式来告警,看这里吧,拉到最下面可以看到支持微信,钉钉目前是不支持的,有第三方的,我将来会对接企业微信的,暂时现用邮件吧,下面看看 alertmanager 的告警状态吧。
告警状态
目前 alertmanager 告警状态分为三种,如下
| 值 | 说明 |
|---|---|
| Inactive | 什么都没有发生 |
| Pending | 已触发阈值,但未满足告警持续时间,for 时间 |
| Firing | 已触发阈值且满足告警持续时间,通知 alertmanager 你可以发送告警了 |
在这个阶段是有个时间的,并不是出现问题告警会马上发出去,这个时间包含了数据采集时间、告警评估时间,这两个时间是在 prometheus 中配置的,也就是这里,
1 | global: |
目前是十五秒采集一次数据,评估告警规则时间也是十五秒,这个评估告警规则的时间就是我每隔多长时间要进行一次评估是否到达的阈值了,说白了这东西的目的就是为了减少告警的次数,更加精确的判断当前的状态是不是 ok 的,下面在看看告警的分配
告警的分配
具体告警要怎么去分配,也是在 alertmanager 中配置的,也就是这一段,
1 | route: |
这就是设置告警的分发策略了,这个 route 可以拆分成多个子路由,目前所有的告警都会发送到名为 email 的接收器里面,email 接收器的规则也是在配置文件中指定的,也就是这一段,
1 | receivers: |
接收器目前只有一个名为 email 的,也可以有多个,如果你有什么特殊需求,需要将不同类型的告警发送给不同的人,就需要配置多个接收器去区分了,如下,
1 | global: |
我就不掩饰了,配置其实很简单,演示很麻烦撒,算了算了,过,下面看一哈告警收敛
告警收敛
收敛就是尽量压缩告警邮件的数量,太多了谁都会懵逼,可能有些关键的被淹没了,alertmanager 中有很多收敛机制,最主要的就是分组抑制静默,alertmanager 收到告警之后他会先进行分组,然后进入通知队列,这个队列会对通知的邮件进行抑制静默,再根据 router 将告警路由到不同的接收器,这就是 alertmanager 收到一个告警后经历的阶段,只是一个大概的情况,下面深入了解一下这几个阶段到底是什么原理怎么去配置,先来简单看一下他们的定义
| 机制 | 说明 |
|---|---|
| 分组 (group) | 将类似性质的告警合并为单个进行通知 |
| 抑制 (Inhibition) | 当告警发生后,停止重复发送由此告警引发的其他告警 |
| 静默 (Silences) | 是一种简单的特定时间静音提醒的机制 |
分组
举个例子,比如说我在阿里云有 10 台服务器,但是我忘续费了,结果服务器到期都被停掉了 (真实发生过),这时候 node_exports 肯定也无法访问了,服务器都停了,这时候普罗米修斯发现这 10 个服务器都凉了,我要准备通知 alertmanager 告警了,在不做分组的情况下你的告警媒介会有十条信息发出来,这种情况下我们可以他这些信息合并到一起撒,一条信息列出哪些服务器凉了。
其实分组设置最开始的时候我就做了,这一段就是设置分组的,
1 | route: |
这里配置了分组的依据,默认就是 alertname,这个名字可以随便写的,做了分组之后他会去匹配你告警时的名字,告警的名字是在这里配置的,
1 | - alert: 采集器凉了 |
如果是相同名字的告警在一定时间内出现多条,这个一定时间指的就是 group_wait 的时间,那么多条就会合并成一条告警信息发出来,这个之前就配置了,所以在我停掉 mysql&docker 采集器之后他就把这两条告警合并成一条信息发了出来,也就是这张图,上面贴过了。
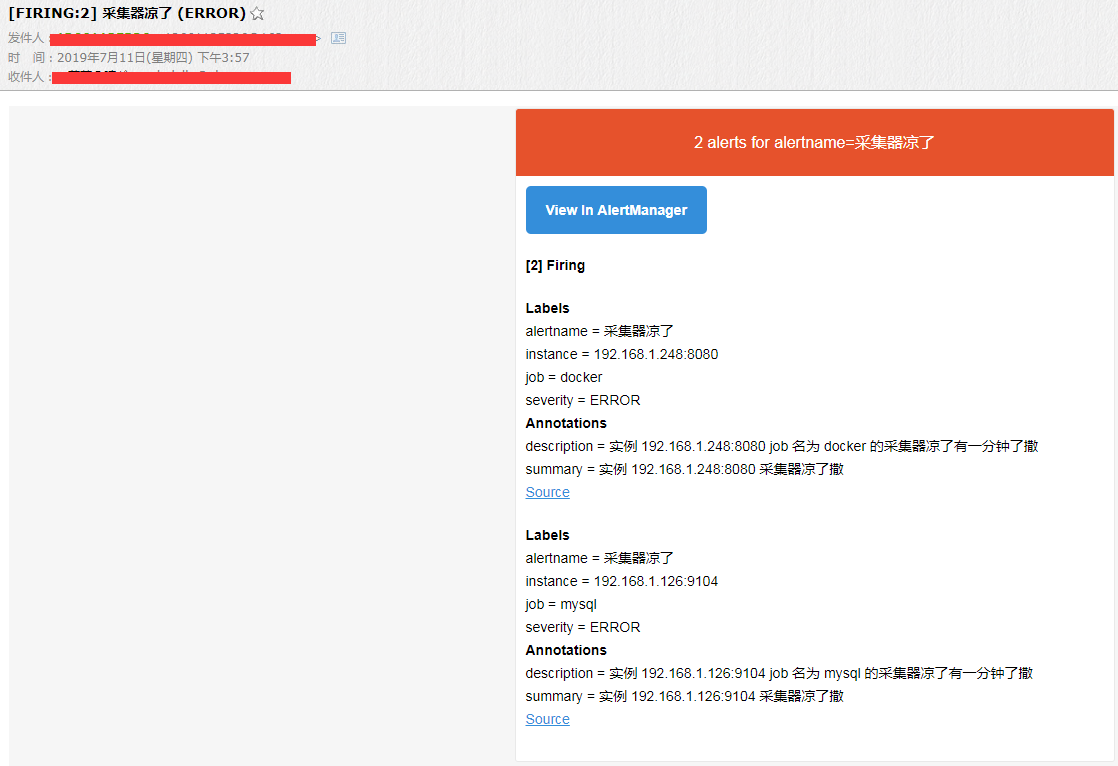
这两条的告警名字都是采集器凉了撒,而且在十秒钟之内出现了两条,所以就被合并成一条发出来了,分组的目的就是为了减少告警信息的数量,同类告警聚合,所以现在总结一下配置分组的参数。
1 | group_by: ['alertname'] #根据标签进行alert分组,可以写多个 |
抑制
他的主要作用就是消除冗余告警,我们会受到一个关键的告警信息,这个也是在 alertmanager 中配置的,我标签只留了一个,
1 | inhibit_rules: |
这段配置意思就是当我收到一个告警级别为 critical 时,他就会抑制掉 warning 这个级别的告警,这个告警等级是在你编写规则的时候定义的,最后一行就是要对哪些告警做抑制,通过标签匹配的,我这里只留了一个 instance,举个最简单的例子,当现在 alertmanager 先收到一条 critical、又收到一条 warning 且 instance 值一致的两条告警他的处理逻辑是怎样的。
我现在监控 nginx,nginx 宕掉的告警级别为 warning,宿主机宕掉的告警级别为 critical,譬如说现在我跑 nginx 的服务器凉了,这时候 nginx 肯定也凉了,普罗米修斯发现后通知 alertmanager,普罗米修斯发过来的是两条告警信息,一条是宿主机凉了的,一条是 nginx 凉了的,alertmanager 收到之后,发现告警级别一条是 critical,一条是 warning,而且 instance 标签值一致,也就是说这是在一台机器上发生的,所以他就会只发一条 critical 的告警出来,warning 的就被抑制掉了,我们收到的就是服务器凉了的通知,大概就是这样,暂时不演示了。
静默
就是一个简单的特定时间静音提醒的机制,主要是使用标签匹配这一批不发送告警,譬如说我某天要对服务器进行维护,可能会涉及到服务器重启,在这期间肯定会有 N 多告警发出来,所以你可以子啊这期间配置一个静默,这类的告警就不要发了,我知道发生了啥子事情,配置静默就很简单了,直接在 web 页面配置就行了,9093 端口,
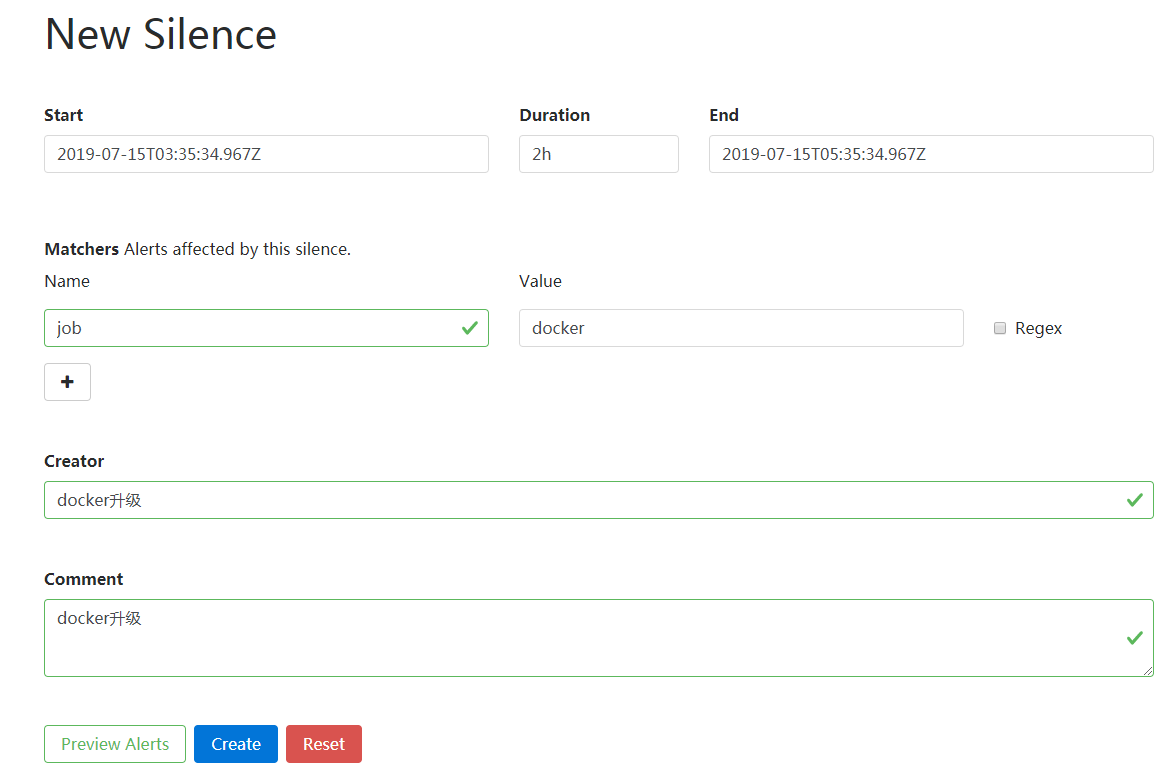
选择开始时间结束时间,通过标签匹配去做,我匹配了 job=docker 的机器,创建,所以我先在把容器采集器停掉也不会有告警出来了,我就不停了,就是这样配置,比较简单,扯了一堆,是时候自己写一个告警规则了,结合上面一切的东西。
编写告警规则例子
来监控内存吧,内存使用率超过 80 我就要告警了,还是先需要写 sql,把我想要的值查出来,所以要查当前内存使用率大于百分之八十的 sql 如下,
1 | (node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes) / (node_memory_MemTotal_bytes )* 100 > 80 |
下面就是要写规则了,我写的规则如下,顺便把之前的规则也改了一下,
1 | [root@rj-bai /usr/local/prometheus/rules]# cat memory.yml |
这样就可以了,我又把明月三千里加入到监控,也就是安装了 node_exports,现在也能正常获取到使用率了,下面试试上面提到的那个告警分配,我要把明月三千里的告警信息发送到我另一个邮箱,job 名字 mysql,
1 | - job_name: 'mysql' |
重启一下撒,能看到这些,

然后去配置一下告警的分配,我要把关于明月三千里的告警发送到另一个邮箱,所以这里改了一哈,
1 | route: |
所以一会收到明月三千里的邮件是我 cn 的邮箱,这样就可以了撒,重启 alertmanager,为了让他发出告警邮件,我调一下阈值,改为百分之 20,所以我 com 收到的邮件如下,
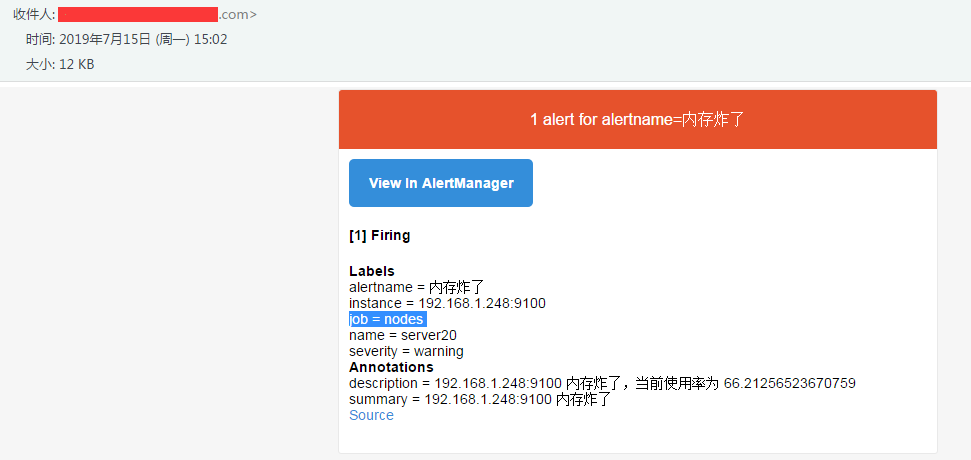
cn 收到的邮件如下
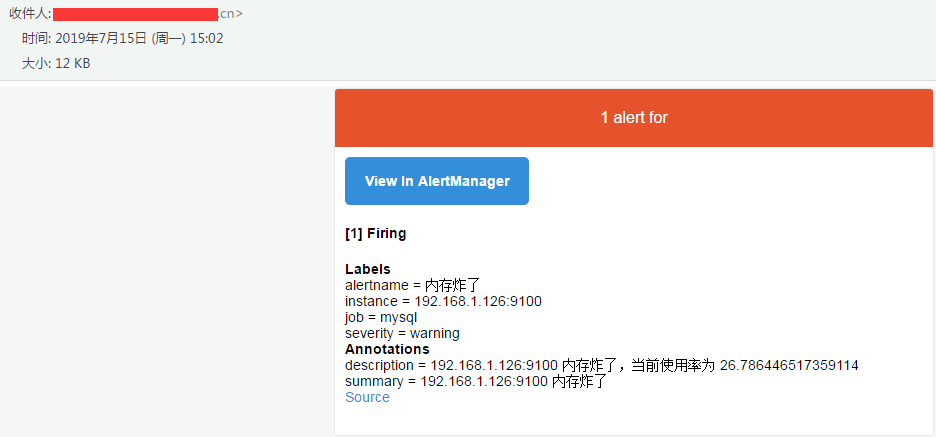
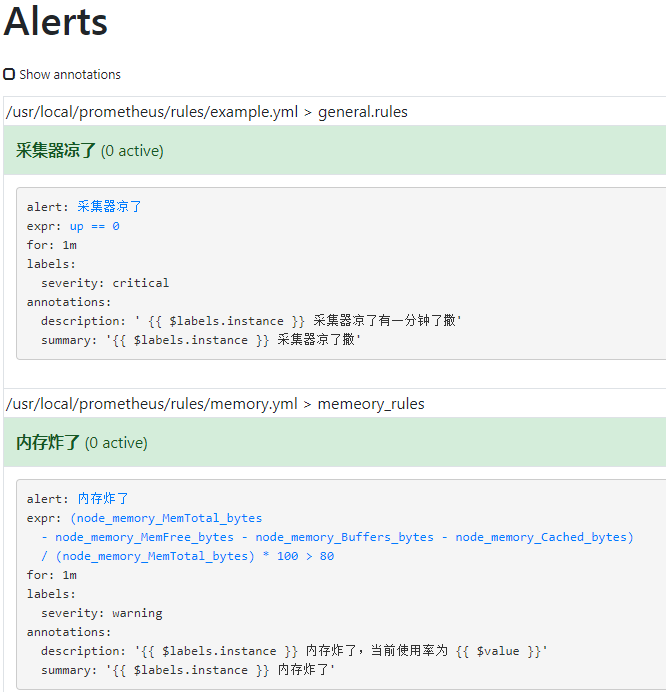
然后再试一下抑制,我再加一个监控项,我要监控 TCP 连接数,状态是 ESTABLISHED 的,超过 300 我就要告警了,定义告警级别为 critical,所以 rule 文件如下,
1 | [root@rj-bai /usr/local/prometheus/rules]# cat tcp-established.yml |
重启后看页面,
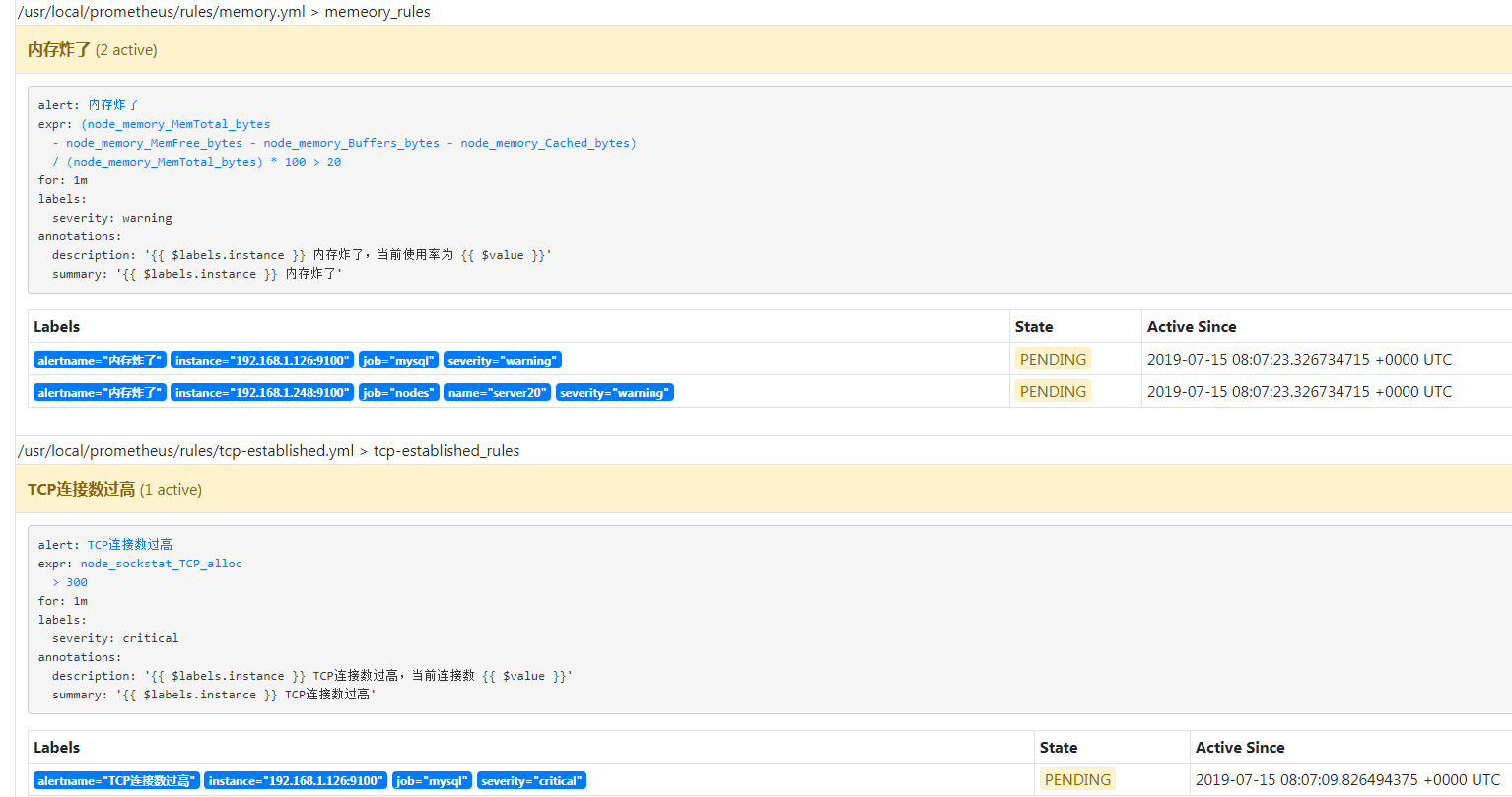
有三条告警已经进入 Pending 状态了,没意外的话 cn 邮箱只有一条告诉你连接数过高的告警信息发出来了,内存使用率过高的就会被抑制,看一下,
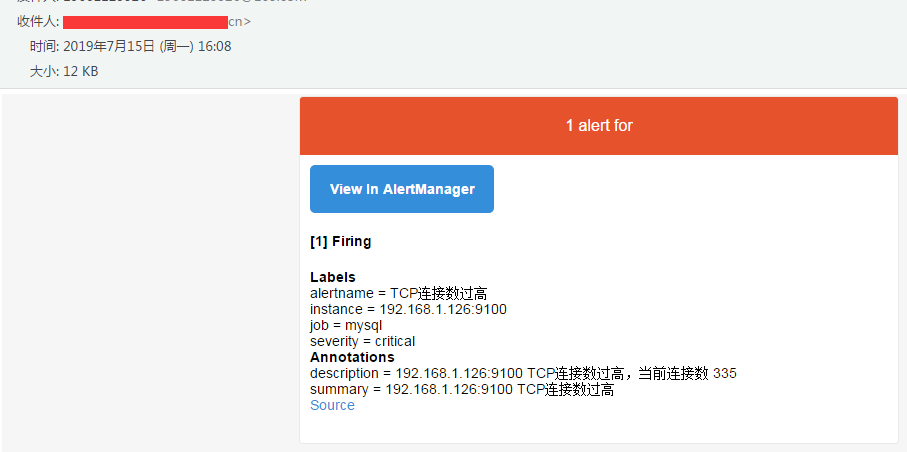
所以这条已经被抑制了,
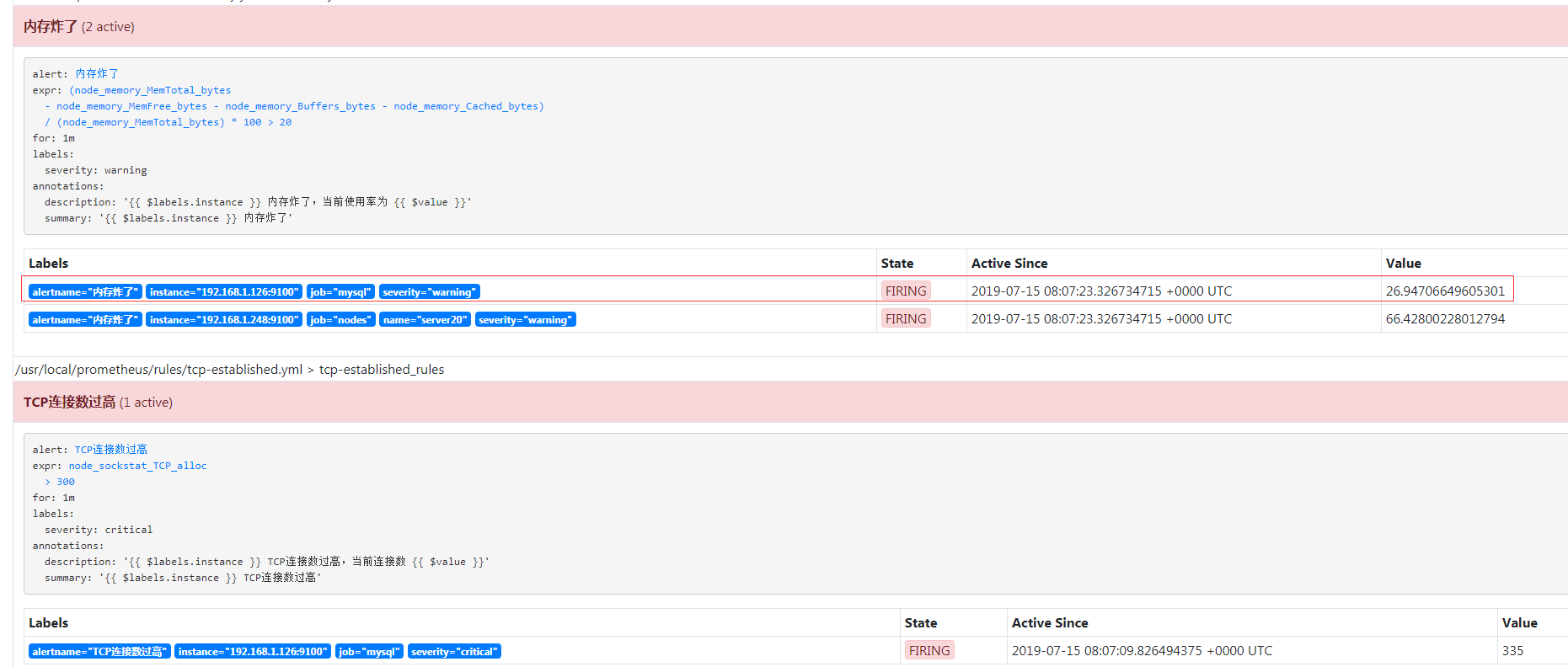
248 服务器不受影响,com 邮箱还是会收到内存炸了的告警,
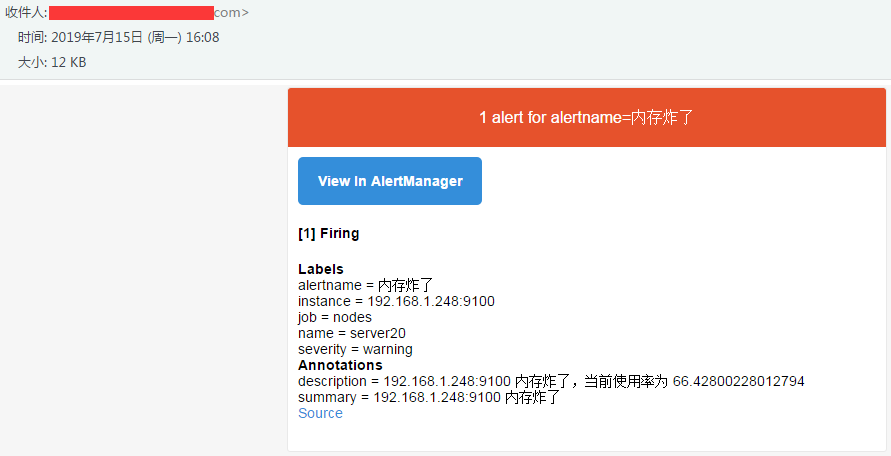
就是这样,你想编写其他的告警规则流程和上面是一样的,告警的分配和抑制不是必需的,自行琢磨吧,下一篇准备重写 K8S 监控方面的东西,了解这些东西之后之后就应该很简单了撒,本篇就这样,过。


